Agentic 范式正在重塑 AI 与数据交互的方式。但一个关键问题始终没有被认真回答:Agent 应该用什么"语言"来操作数据?
绝大多数 Data Agent 产品选择了 Python——让 LLM 生成 pandas 代码,在沙箱里执行。这条路看起来自然,走起来却越来越窄。InfiniSynapse 选择了一条完全不同的路:用一门为 AI 设计的数据分析语言 InfiniSQL 作为 Agent 的工具语言。
这篇文章不是功能介绍,而是一次技术层面的追问:为什么 InfiniSQL 的语言设计与 Agentic 工具调用范式是同构的?为什么这种同构性能产生远超 Python 方式的效果?
一、先理解 Agentic 范式在数据分析中意味着什么
Agentic 范式不是一个模糊的概念。在数据分析场景中,它有三个精确的特征:
多步工具调用。 Agent 不是一次性生成最终答案,而是通过多次调用工具,每一步获取局部信息,逐步逼近完整洞察。一次完整的数据分析可能涉及 10-50 次工具调用——从查看表结构、试探性取样、维度下钻、异常检测到交叉验证。
状态累积。 前序调用的结果必须能被后续调用引用。Agent 在第 3 步查出的"华东区销售数据",必须能在第 7 步被直接使用,而不是重新查一遍。所有的中间结果构成了一棵数据探索树。
动态决策。 每一步的输出决定下一步的方向。Agent 看到华东区数据异常,才决定深入下钻;看到需要客户维度,才决定加载新的数据源。这不是预设好的流程,而是根据数据现实做出的实时判断。
这三个特征对工具语言提出了严苛的要求:语言必须支持低成本的状态累积、动态的数据源接入、以及极低的每步错误率。
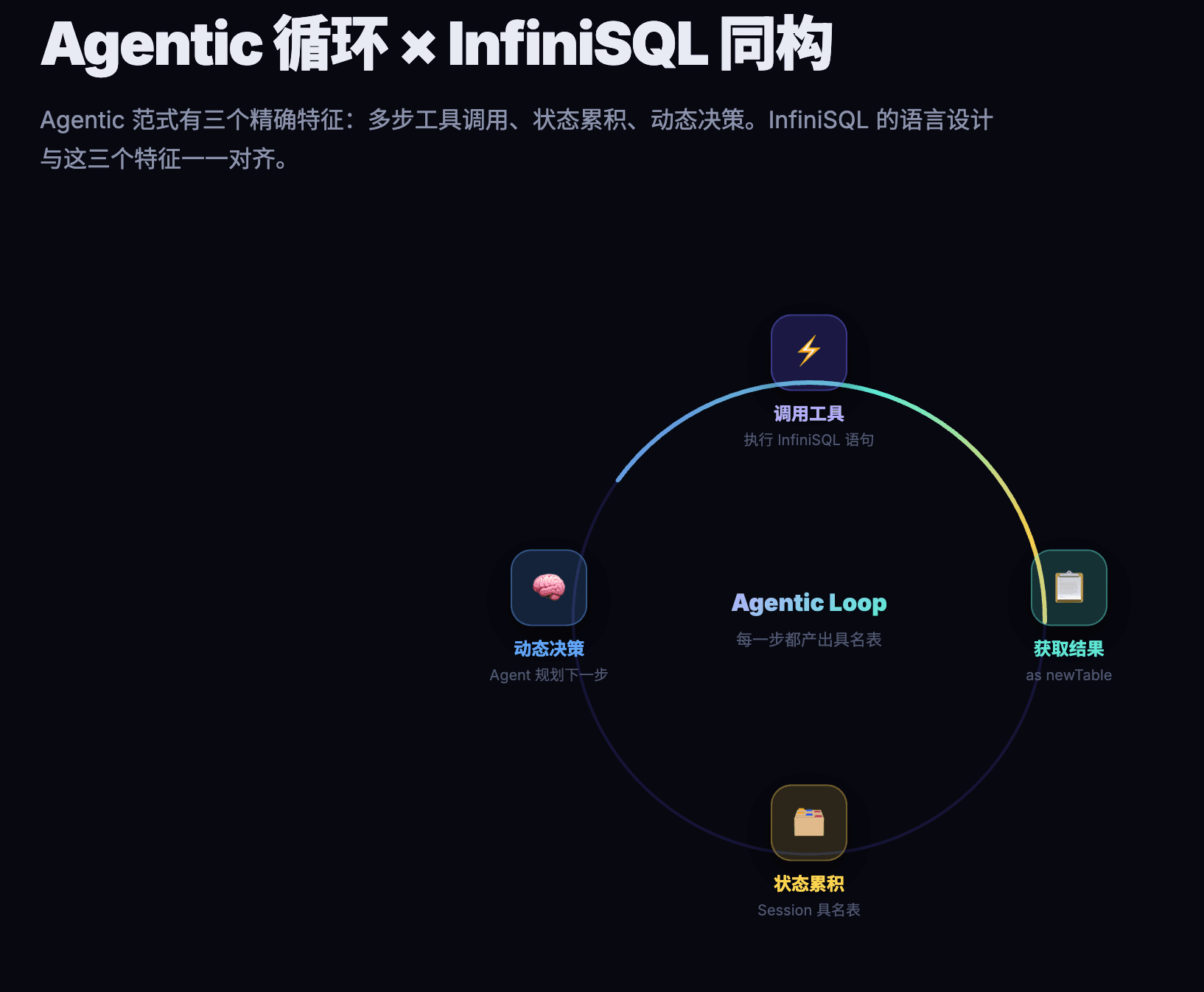
二、InfiniSQL 的语言设计为什么与这三个特征精确对齐
2.1 select ... as newTable:天然的状态累积机制
InfiniSQL 的语法规则要求每条 select 语句必须以 as tableName 结尾。这不是语法糖——这是一个深刻的架构决策。
看一下 InfiniSQL 的 ANTLR 语法定义:
SELECT ~(';')* as tableName
再看引擎的实现:当一条 select 执行完毕后,引擎自动将结果注册为 Spark 的临时视图(df.createOrReplaceTempView(tableName)),在整个 session 内可被后续语句直接引用。
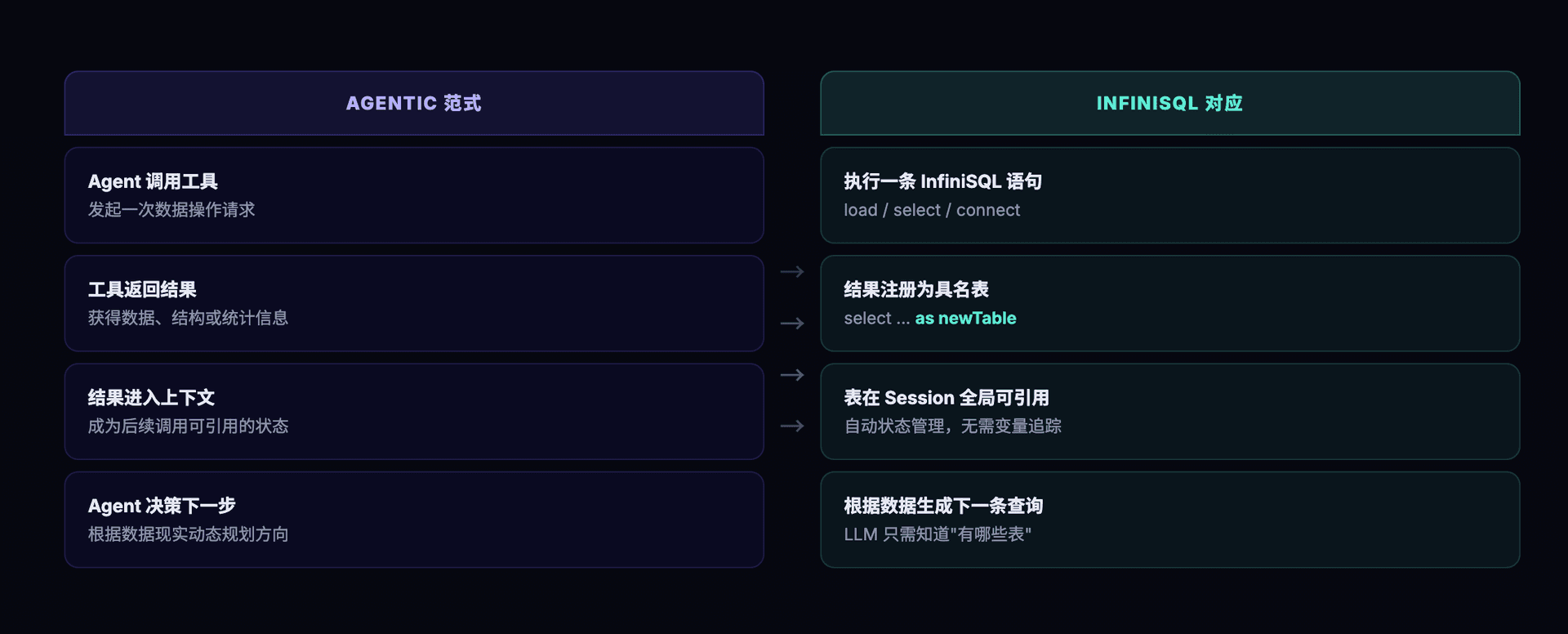
每次工具调用(即每条 InfiniSQL 语句)的结果都自动成为一张具名表。 不需要额外的状态管理层,不需要 Agent 记住之前用了什么变量名。这与 Agentic 范式的状态累积是完美同构的:
| Agentic 范式 | InfiniSQL 对应 |
|---|---|
| Agent 调用工具 | 执行一条 InfiniSQL 语句 |
| 工具返回结果 | 查询结果注册为具名表 |
| 结果进入 Agent 上下文 | 表在 session 内全局可引用 |
| Agent 决定下一步操作 | 根据数据结果生成下一条查询 |
传统 SQL 不具备这个能力。标准 SQL 的 SELECT 返回结果集后即消失,要复用必须写 CTE、子查询或手动创建临时表——这些都增加了 LLM 的认知负担和出错概率。
2.2 load ... as tableName:跨源数据的统一抽象
InfiniSQL 的 load 语法将任何数据源都统一抽象为一张表:
-- 连接本地 MySQL
connect jdbc where
url="jdbc:mysql://127.0.0.1:3306/business_db"
and driver="com.mysql.jdbc.Driver"
and user="xxx" and password="xxx"
as mysql_db;
-- 连接云端 PostgreSQL
connect jdbc where
url="jdbc:postgresql://cloud.example.com:5432/analytics"
and driver="org.postgresql.Driver"
and user="xxx" and password="xxx"
as pg_cloud;
-- 加载不同来源的数据,它们在同一个 session 里共存
load jdbc.`mysql_db.orders` as orders;
load jdbc.`pg_cloud.customers` as customers;
load csv.`/data/local_sales.csv` as local_sales;
三条 load 之后,来自本地文件、本地 MySQL、远端云 PostgreSQL 的数据在同一个 session 里共存为三张表,可以直接做 JOIN:
select o.order_id, c.name, l.region
from orders o
left join customers c on o.customer_id = c.id
left join local_sales l on o.order_id = l.order_id
as cross_source_analysis;
对 Agentic 范式而言,这意味着 Agent 可以在探索过程中的任何时刻动态加载新的数据源。发现需要对比 Excel 数据?生成一条 load 语句即可——新数据立即可用,前面探索过的所有表依然存在。不需要重新建立环境,不需要预先配置 ETL 管道。
2.3 共享 Session:Agentic 探索的持久化工作空间
InfiniSQL 的 session 机制(sessionPerUser / sessionPerRequest)以及变量作用域(request / session / application)为 Agent 提供了一个持久化的工作空间:
- session 级别的表在整个对话过程中持续有效
- Agent 第 1 步 load 的表,到第 20 步依然可以引用
- 中间每一个
select ... as someTable都在 session 里形成了一棵可回溯的数据探索树 - 变量设置为
session作用域后可跨语句复用
这正是 Agentic 范式需要的:一个有记忆的、累积式的工作环境。

三、为什么"写 Python 代码"的方式是结构性劣势
竞品(Julius AI、camelAI、Fabi.ai 等)采用的 Agentic 范式是让 LLM 生成 Python 代码(主要是 pandas),在沙箱中执行。在 Agentic 多步探索场景下,这种方式存在五个结构性劣势:
3.1 状态管理是脆弱的
Python 方式下,Agent 每次调用生成一段代码。前一段代码的结果存在某个 DataFrame 变量里,后一段代码要引用它,LLM 必须"记住"变量名。
问题在于:随着探索步骤增多,变量命名空间越来越复杂。LLM 可能忘记之前用了 df_orders_filtered 还是 filtered_orders,可能在第 15 步误覆盖了第 3 步定义的变量。
InfiniSQL 没有这个问题。select ... as orders_filtered 注册的表名是确定性的、全局可见的。Agent 只需要知道"当前 session 里有哪些表"——这是一个扁平的列表,不是一棵代码变量的依赖树。
3.2 每一步的错误面太大
生成一段 Python 代码涉及:API 调用(pd.read_sql()、pd.merge()、groupby())、类型处理(astype()、to_datetime())、异常捕获(try/except)、字符串拼接(SQL 注入风险)等。LLM 在任何一个环节都可能出错,而且错误类型多样——语法错误、逻辑错误、API 版本不兼容、内存溢出。
InfiniSQL 的每次调用就是一条声明式语句。语法约束极强(必须以 as tableName 结尾),中间部分是标准 SQL,LLM 出错的空间被大幅压缩。
更关键的是,InfiniSQL 的错误提示是为 LLM 设计的:
InfiniSQL Parser error: Select statement is missing 'as tableName' clause.
InfiniSQL select statements must end with 'as tableName'.
Example: select * from table1 as result_table;
当 LLM 忘记写 as tableName 时,错误信息直接告诉它该怎么改——Agent 的自我纠错几乎不需要额外推理。
3.3 多源融合遇到内存天花板
Python/pandas 方式做跨源关联分析的流程是:先从数据库 A 拉数据到内存(pd.read_sql()),再从数据库 B 拉数据到内存,然后 pd.merge()。
32GB 内存的沙箱环境下,百万行级别的表就开始卡顿。更不用说把本地 Excel 和远程 Hive 大数据仓库做联合分析。
InfiniSQL 的跨源 JOIN 在分布式引擎上执行。directQuery 机制还允许将原生查询下推到数据源:
load jdbc.`mysql_instance.large_table` where directQuery='''
select region, sum(amount) as total from large_table group by region
''' as aggregated_result;
聚合在 MySQL 端完成,只有结果传回——这是计算下推,不是数据搬迁。
3.4 探索资产无法沉淀
Julius AI 被用户吐槽最多的痛点之一:每次对话生成的代码是一次性的,无法复用之前写过的代码或已构建的数据视图。
这是 Python 方式的结构性限制——代码块之间没有统一的命名空间,上一轮对话的 DataFrame 变量在新对话中消失了。
InfiniSQL 的 session 里,所有 load 和 select ... as 产出的表持续存在。Agent 可以在任何时刻回顾之前的探索成果,在已有表的基础上做进一步分析。探索的过程本身就是资产的积累。
3.5 LLM 的认知负担不在同一个量级
pandas 有几百个 API(read_csv、merge、groupby、pivot_table、apply、melt、stack、unstack……),每个 API 有多种参数组合。LLM 需要在这个巨大的 API 空间里做选择。
InfiniSQL 的核心关键字只有:load、connect、select ... as、save、set。中间的查询部分兼容标准 SQL,LLM 已经在训练数据中大量见过。认知负担的差距是数量级的。
| 维度 | Python/pandas | InfiniSQL |
|---|---|---|
| 状态累积 | 变量命名空间,易冲突、易遗忘 | 具名表自动注册,session 全局可见 |
| 每步错误率 | 高(API 多、类型复杂、异常处理) | 极低(语法简、约束强、错误提示友好) |
| 多源融合 | 内存瓶颈(拉数据 → merge) | 分布式引擎 + 计算下推 |
| 探索资产复用 | 一次性代码,难以复用 | 具名表持续存在,随时可引用 |
| LLM 认知负担 | 几百个 API,参数组合爆炸 | 几个关键字 + 标准 SQL |
人类数据分析师做分析,用的是 SQL 而不是 Python——Agent 也应该如此。
这里有一个常常被忽视的事实:SQL 本来就是为数据而生的语言。人类分析师在数据库前坐下来,第一反应是写 SQL,不是写 Python 脚本。为什么?因为 SQL 是声明式的——你只需要说"要什么",不需要说"怎么做"。SELECT region, SUM(amount) FROM orders GROUP BY region 一句话表达的分析意图,用 Python 要写 df.groupby('region')['amount'].sum().reset_index() 再加上一堆类型转换和异常处理。
Agent 和人类面对的是同一个问题:从数据中获取洞察。 既然人类选择了 SQL 作为与数据对话的语言,Agent 没有理由要绕道去写 Python。
而 InfiniSQL 做的事情,是把标准 SQL 改造得更适合 Agentic 范式:
- 标准 SQL 的
SELECT结果是一次性的——InfiniSQL 加上as newTable,让每次查询自动沉淀为 session 中的具名表 - 标准 SQL 不能跨数据源——InfiniSQL 加上
connect+load,让 Agent 动态接入任何数据源 - 标准 SQL 没有机器学习——InfiniSQL 加上
train+register,让模型训练和预测融入同一条管道
SQL 本身就是对的选择,InfiniSQL 只是让它变得更适合 Agent 使用。 这不是"发明一种新语言",而是在数据分析最自然的语言基础上,精确补足了 Agentic 范式所需要的状态累积、多源融合和管道化能力。
四、更深层的契合:机器学习也是"表"的延伸
InfiniSQL 与 Agentic 范式的契合不止于数据查询——它还把机器学习无缝融入了同一套管道。
传统机器学习天然以数据为中心:准备特征 → 训练模型 → 预测 → 评估。在 Python 世界里,这需要从 pandas 跳到 scikit-learn 或 PyTorch,切换一整套 API 体系。但在 InfiniSQL 中,机器学习是 SQL 管道的自然延伸——模型训练的输入就是 select 做完特征工程后产出的"表"。
4.1 特征工程 → 训练 → 预测:一条管道贯穿到底
看一个完整的 InfiniSQL 机器学习流程:
-- 第1步:加载原始数据(和前面的数据探索完全一致的 load 语法)
load jdbc.`mysql_db.iris_data` as rawData;
-- 第2步:特征工程——用标准 SQL 的 select 完成
select
vec_dense(array(sepal_length, sepal_width, petal_length, petal_width)) as features,
cast(species as double) as label
from rawData as trainData;
-- 第3步:训练模型——输入就是上一步的 "trainData" 表
train trainData as RandomForest.`/models/iris_model` where
keepVersion="true"
and evaluateTable="trainData"
and `fitParam.0.labelCol`="label"
and `fitParam.0.featuresCol`="features"
and `fitParam.0.maxDepth`="5"
and `fitParam.0.numTrees`="10";
-- 第4步:注册模型为 SQL 函数
register RandomForest.`/models/iris_model` as iris_predict;
-- 第5步:预测——在 select 里直接调用模型函数
select
features,
label as actual,
vec_argmax(iris_predict(features)) as predicted
from trainData as predictions;
注意看这个流程的关键特征:
train trainData里的trainData就是上一步select ... as trainData产出的表——特征工程的结果直接流入训练,无需格式转换、无需 API 切换register ... as iris_predict把训练好的模型变成一个 SQL 函数——之后可以在任何select语句里直接调用- 整个流程从
load到select(特征工程)到train到register到select(预测),全部在同一个 session 里,用同一套语言
4.2 为什么这对 Agentic 范式意义重大
在 Agentic 数据探索中,Agent 经常会发现"数据里有可预测的模式"——比如发现 VIP 客户的购买行为有规律,想做一个预测模型。
在 Python 方式下,Agent 需要:
- 从 pandas 切换到 scikit-learn
- 把 DataFrame 转为 numpy array
- 学习一套完全不同的 API(
fit(),predict(),score()) - 处理模型序列化和加载
在 InfiniSQL 下,Agent 的操作完全无缝:
- 用
select做特征工程(它一直在做的事情) - 用
train训练(输入就是它刚select出来的表) - 用
register注册模型函数 - 用
select+ 模型函数做预测(它依然在写select)
Agent 不需要切换语言、不需要学习新的 API、不需要做格式转换。 机器学习只是多了 train 和 register 两个关键字,其余一切——数据格式(表)、操作方式(select)、状态管理(session)——完全一致。
这意味着 InfiniSQL 的 Agentic 管道可以从"数据查询"自然延伸到"预测建模",而不需要跳出当前范式。Agent 的认知负担几乎没有增加,但能力边界大幅扩展。
4.3 数据探索与机器学习的统一语义
更深层来看,InfiniSQL 实现了一种统一语义:一切皆表,一切操作产出表。
| 操作 | 语法 | 输入 | 输出 |
|---|---|---|---|
| 加载数据 | load ... as | 数据源 | 表 |
| 数据探索 | select ... as | 表 | 表 |
| 特征工程 | select ... as | 表 | 表 |
| 模型训练 | train table as ... | 表 | 模型 |
| 模型注册 | register ... as func | 模型 | SQL 函数 |
| 预测 | select func(x) ... as | 表 + 函数 | 表 |
从 load 到数据探索到特征工程到训练到预测,数据始终以"表"的形态流动。Agent 不需要理解"DataFrame 和 numpy array 的区别",不需要处理"模型对象的序列化"——它只需要知道怎么写 select 和 train。
这就是为什么 InfiniSynapse 能够内置完整的机器学习能力(RandomForest、LinearRegression、NaiveBayes、KMeans 等),而竞品即使通过 Python 调用 scikit-learn,在 Agentic 场景下也难以可靠地完成机器学习任务——因为切换 API 体系意味着切换认知模式,每次切换都是 Agent 出错的风险点。
五、一个具体的 Agentic 探索过程
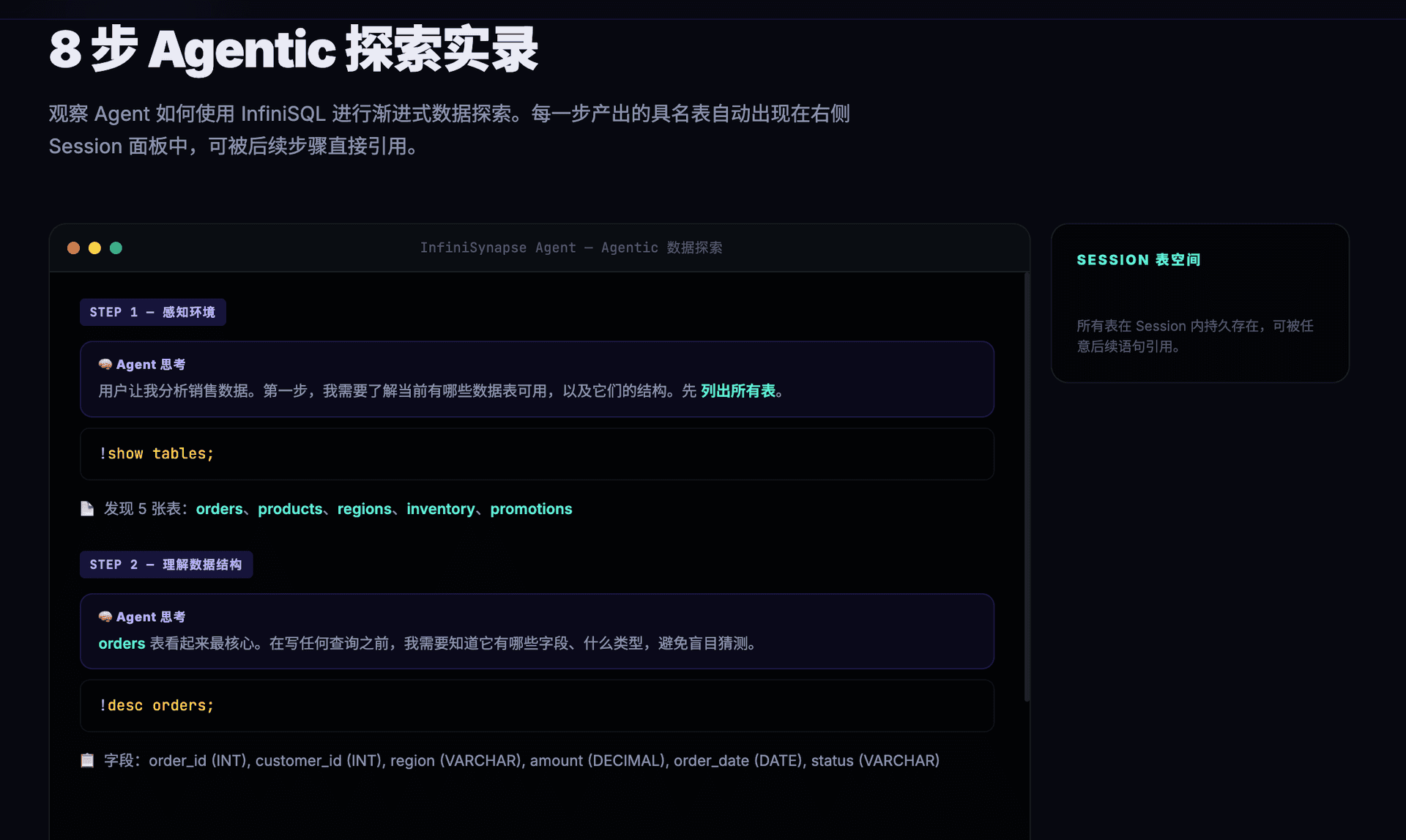
以下是 InfiniSynapse Agent 使用 InfiniSQL 进行一次真实数据探索的过程。注意观察每一步如何产出具名表、如何被后续步骤引用。
Agent 首先感知环境,了解可用的数据表和字段结构:
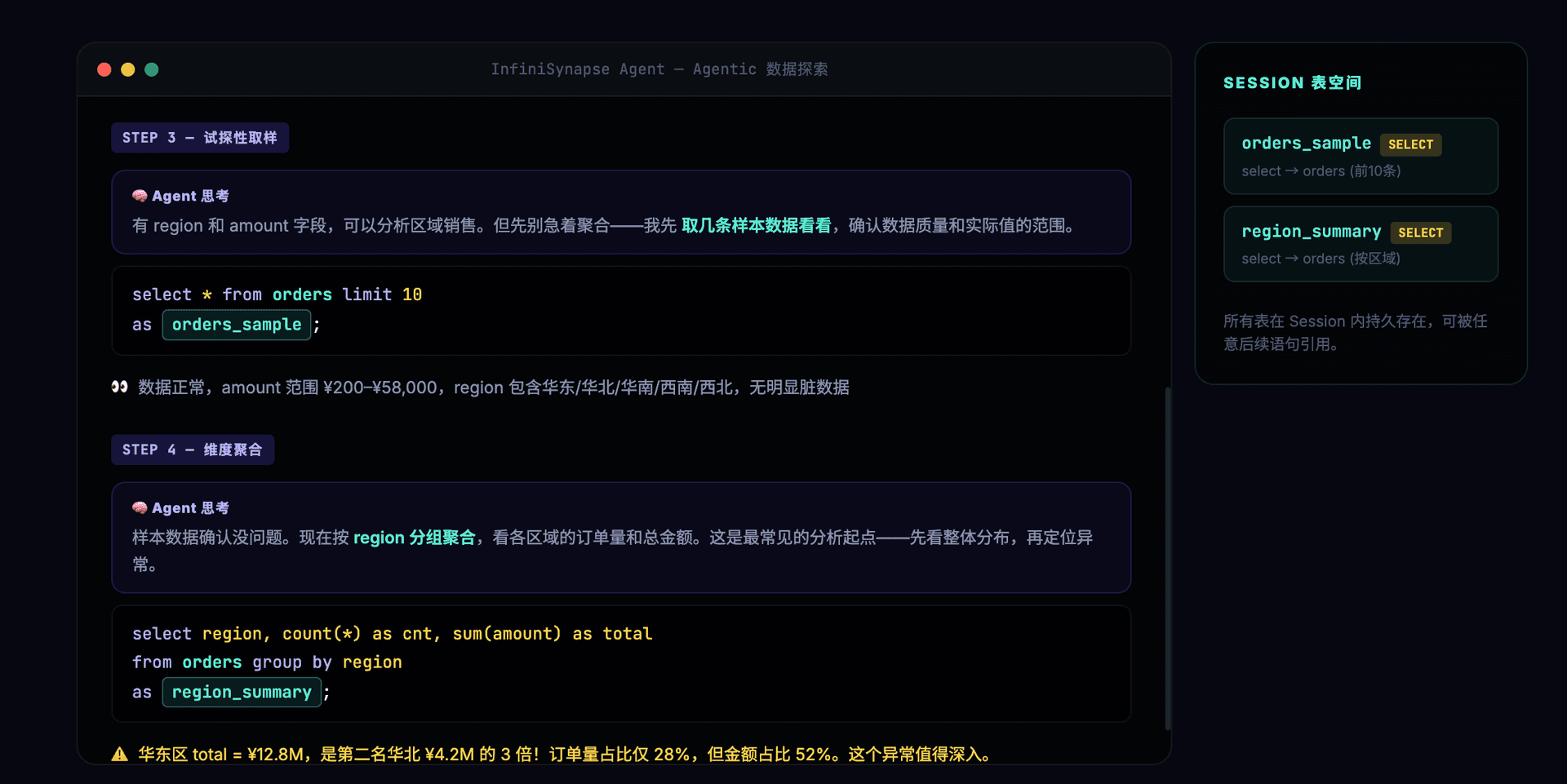
确认数据质量后,Agent 开始试探性取样和维度聚合,发现华东区异常:
Agent 决定深入下钻华东区,发现大额订单集中在少数客户:
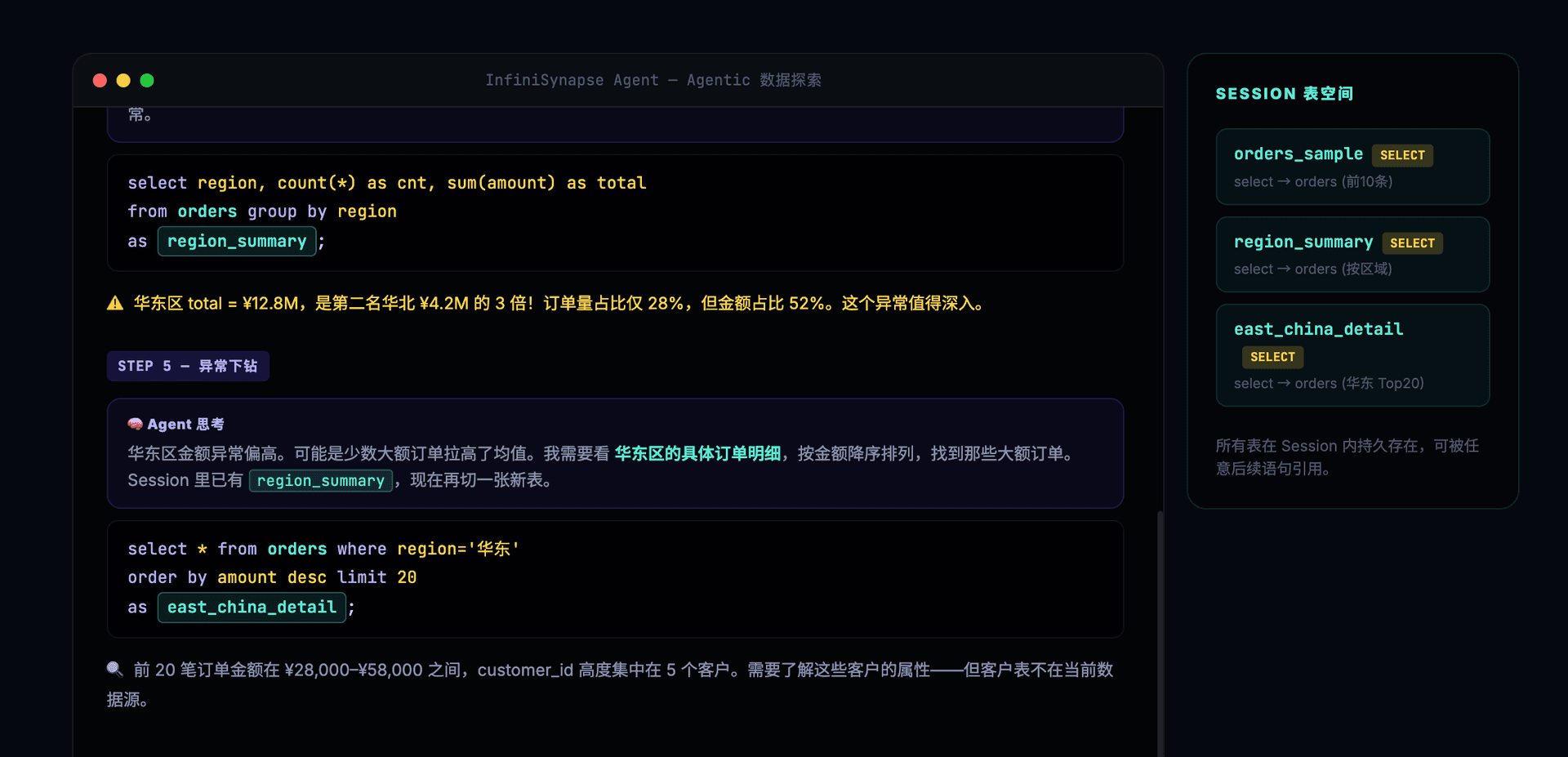
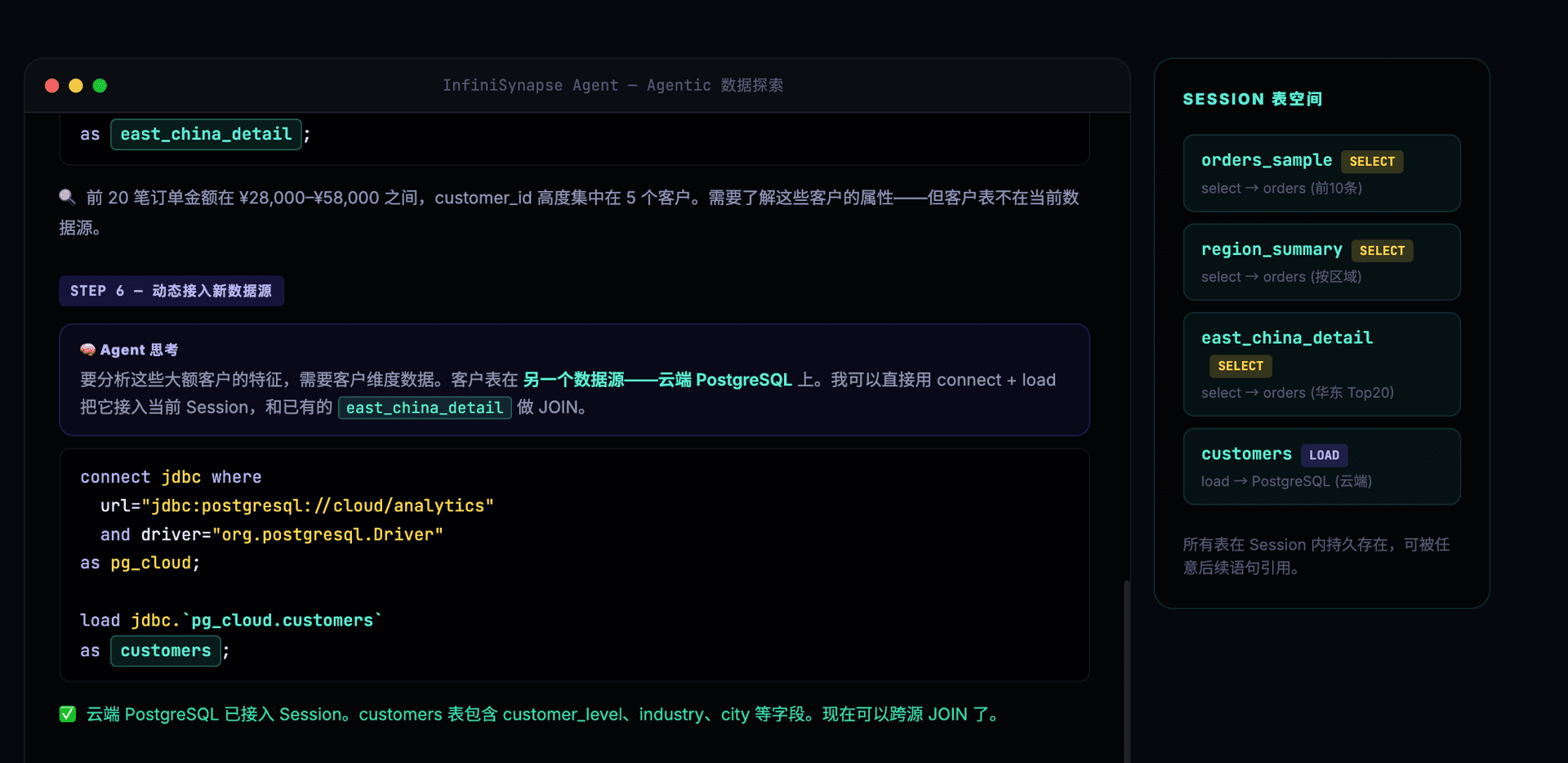
需要客户维度数据——Agent 动态接入云端 PostgreSQL:
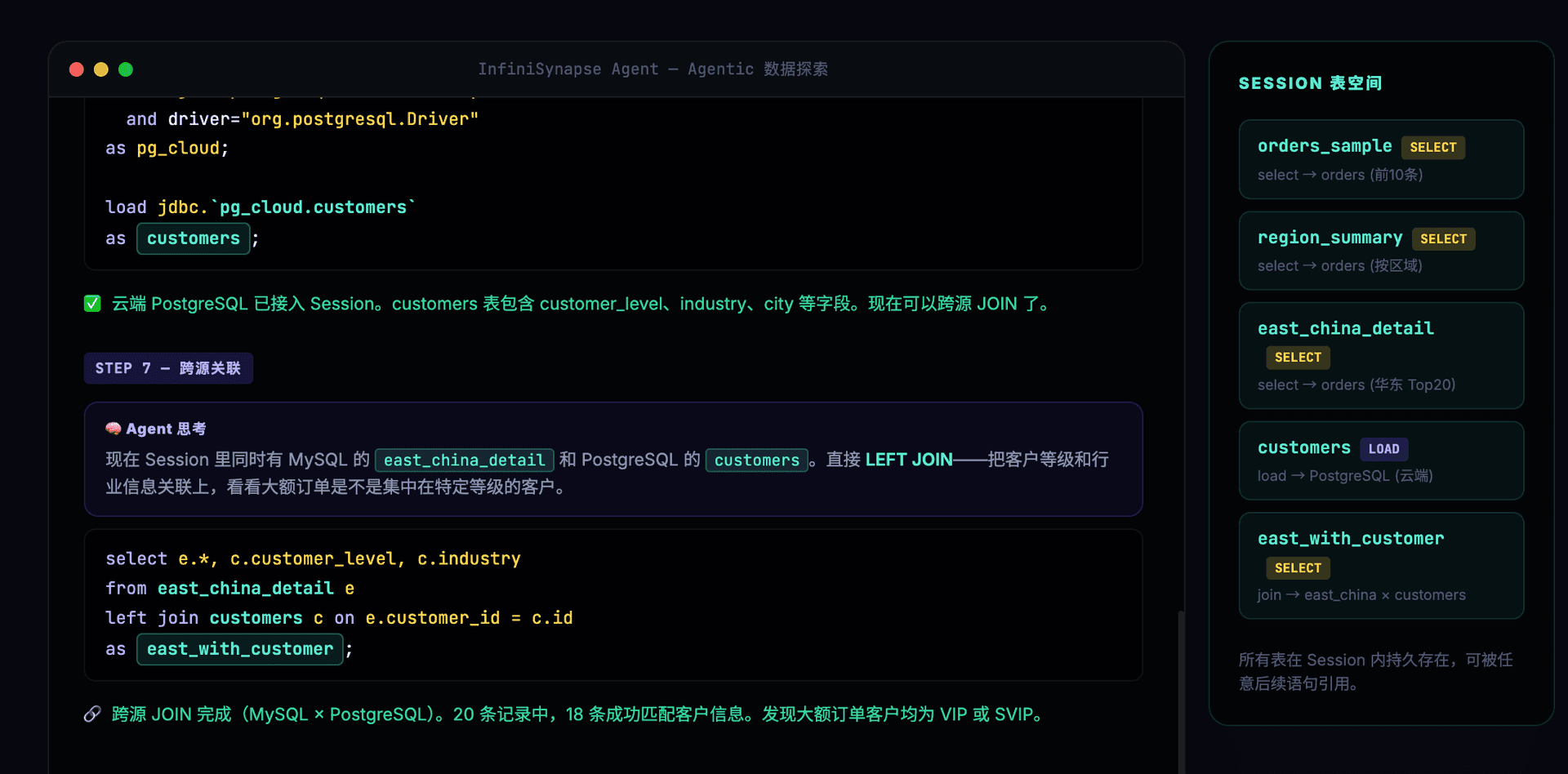
跨源 JOIN,将 MySQL 的订单数据与 PostgreSQL 的客户数据关联:
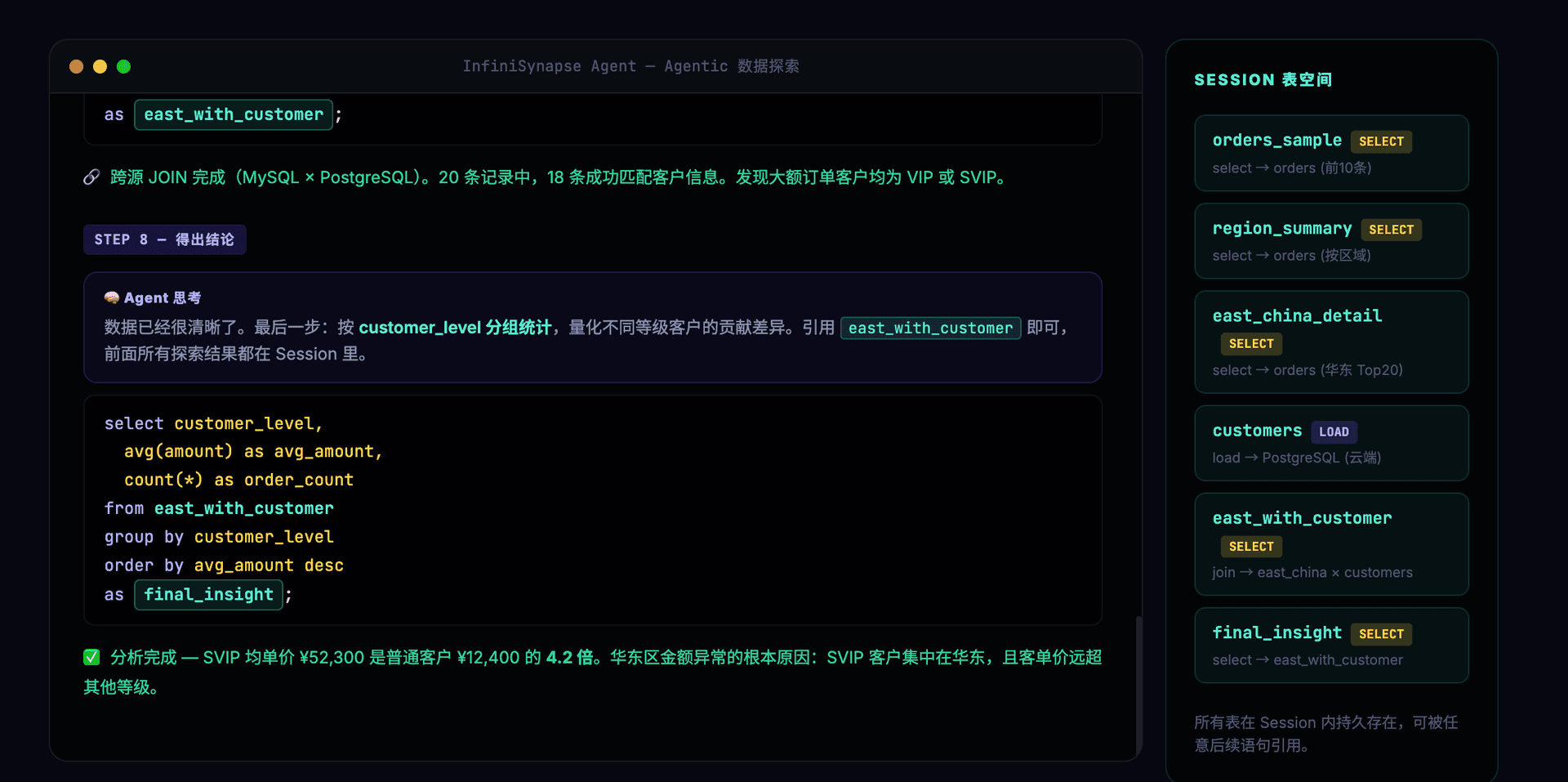
最终得出结论——Session 面板中所有探索产出的具名表一览无余:
以下是这 8 步的完整 InfiniSQL 代码:
-- 第1步:Agent 先看看有什么数据源可用
!show tables;
-- 第2步:看看订单表的结构
!desc orders;
-- 第3步:试探性取一小批数据,了解数据长什么样
select * from orders limit 10 as orders_sample;
-- 第4步:看到数据后,Agent 决定按区域聚合
select region, count(*) as cnt, sum(amount) as total
from orders group by region
as region_summary;
-- 第5步:Agent 看到华东区数据异常,决定深入下钻
select * from orders where region='华东'
order by amount desc limit 20
as east_china_detail;
-- 第6步:发现需要客户维度,动态加载云端 PostgreSQL
connect jdbc where
url="jdbc:postgresql://cloud.example.com/analytics"
and driver="org.postgresql.Driver"
and user="xxx" and password="xxx"
as pg_cloud;
load jdbc.`pg_cloud.customers` as customers;
-- 第7步:跨源 JOIN——复用第5步的探索结果
select e.*, c.customer_level, c.industry
from east_china_detail e
left join customers c on e.customer_id = c.id
as east_china_with_customer;
-- 第8步:基于前面所有探索结果做最终分析
select customer_level,
avg(amount) as avg_amount,
count(*) as order_count,
sum(amount) as total_amount
from east_china_with_customer
group by customer_level
order by total_amount desc
as final_insight;
8 步探索,产出 6 张具名表(orders_sample、region_summary、east_china_detail、customers、east_china_with_customer、final_insight),中途动态接入了一个新数据源(云端 PostgreSQL)。
每一步都简短、独立、可验证。 Agent 看到 region_summary 的结果才决定下钻华东区;看到 east_china_detail 的数据才决定加载客户表做关联分析。这就是 Agentic 范式的"小步探索、动态决策"。
如果用 Python 实现同样的过程:
- 第 6-7 步需要写
psycopg2连接代码、pd.read_sql()拉数据、pd.merge()做关联——至少 15-20 行代码,涉及 3-4 个不同的 API - 第 5 步的结果如果存在
df_east_china变量里,第 7 步必须准确引用这个变量名 - 如果中间任何一步内存溢出,后续所有步骤都无法继续
InfiniSQL 下,每一步都是 1-5 行声明式语句,Agent 出错的概率和纠错的成本都极低。
六、为什么这种结合能产生好的效果
6.1 降低了 Agent 的每步认知成本
Agentic 范式的效果取决于 探索链条能拉多长。如果每一步的错误率是 10%,连续 10 步全部正确的概率只有 35%;如果每一步的错误率降到 2%,连续 10 步全部正确的概率提升到 82%。
InfiniSQL 的极简语法和强约束将每步错误率压到极低,使得 Agent 可以执行 20-50 步的深度探索而不"跑偏"。这就是为什么 InfiniSynapse 用 DeepSeek V3 就能获得优秀效果——不是模型更强,是每步的认知负担更低。
6.2 让数据探索真正"渐进式"
select ... as newTable 的设计让 Agent 的每次探索都有确定性的产出。Agent 不需要在一条巨大的嵌套 SQL 里一步到位,而是可以:
- 先写一个简单查询看看数据
- 基于结果写第二个查询做筛选
- 再基于筛选结果做聚合
- 最后基于聚合结果做对比
每一步都足够简单,Agent 有把握做对;每一步的结果都自动保存,供后续使用。这就是 InfiniSynapse Agent "小步探索、自我纠错"策略的语言基础。
6.3 跨源融合是语言层原生能力
在真实企业环境中,数据分散在不同系统、不同云、甚至不同地理位置。Agentic 探索的价值在于动态发现需要哪些数据源并即时接入。
InfiniSQL 的 connect + load 机制完美支持这一点:
connect只是注册连接信息,不实际拉数据load按需加载,注册为 session 内的表directQuery将计算下推到数据源端执行- 跨源 JOIN 在分布式引擎上完成
Agent 可以在探索的任何阶段接入新数据源——本地 Excel、远程 MySQL、云端 Snowflake——它们都在同一个 session 里,可以自由组合。
竞品的 Python/pandas 方式做不到这一点:不同数据源的 Python 连接库不同(mysql-connector、psycopg2、snowflake-connector……),数据必须全部拉到内存才能 merge,内存成为瓶颈。
6.4 自我纠错的成本趋近于零
当 Agent 的某一步查询返回了异常结果(空表、数据不符预期),纠错的方式只是:生成一条新的 select 语句。 不需要回头修改一整段 Python 代码,不需要重新跑数据加载流程。
InfiniSQL 的错误提示也是为 Agent 设计的——不是给人看的堆栈跟踪,而是结构化的、包含修正示例的提示信息。Agent 读到错误信息后,能立即知道该怎么改。
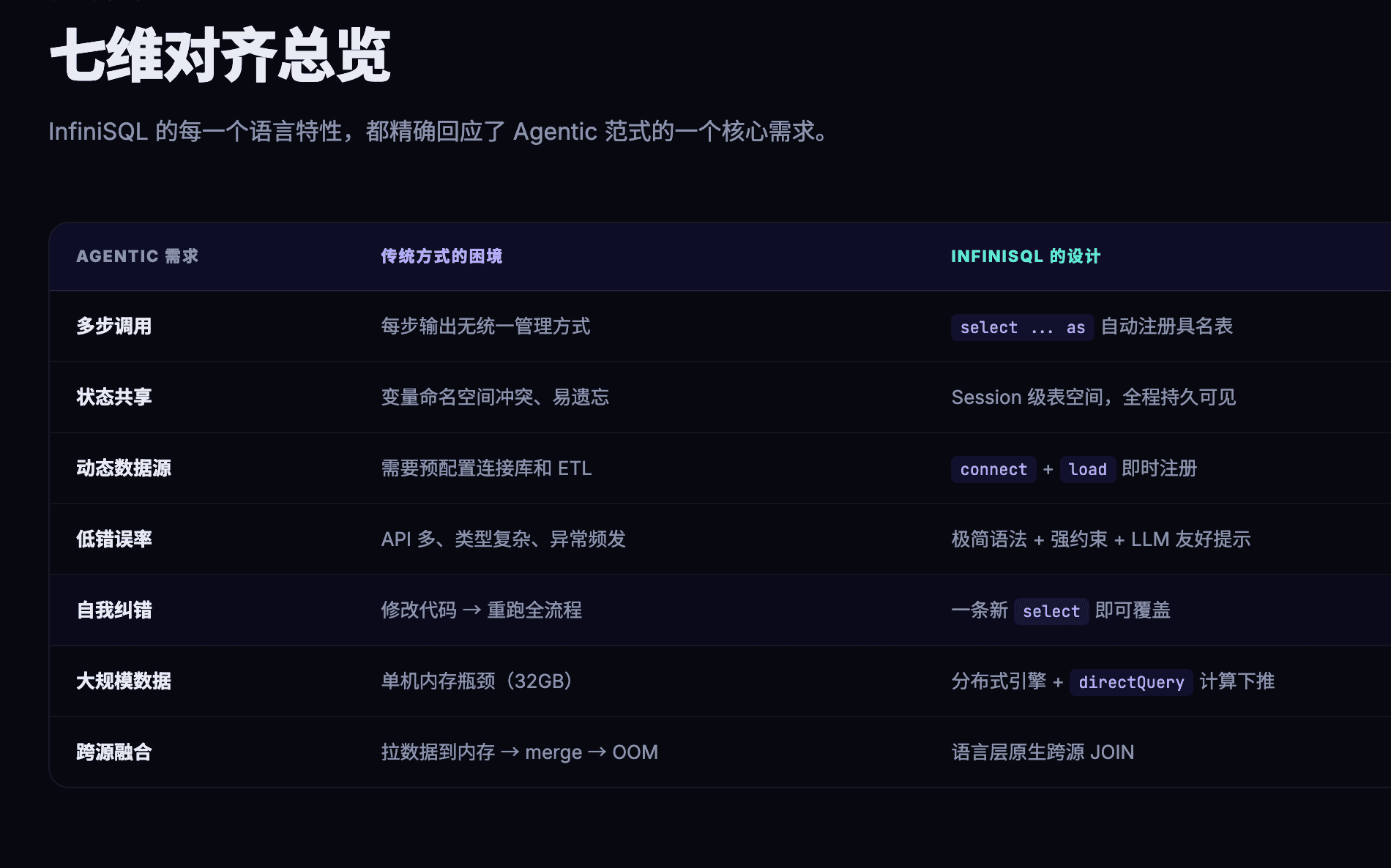
七、总结:语言决定了 Agent 的上限
| 特征 | Agentic 范式的需求 | InfiniSQL 的语言设计 |
|---|---|---|
| 多步调用 | 每步产出可被后续引用的结果 | select ... as newTable 自动注册具名表 |
| 状态共享 | 所有步骤共享同一个上下文 | session 级别的表空间,全程持久 |
| 动态数据源 | 探索中途需要接入新数据 | connect + load 即时注册新数据源 |
| 低错误率 | 高频调用要求每步高可靠 | 极简语法,LLM 认知负担极低 |
| 自我纠错 | 出错后低成本恢复 | 一条新 select 即可覆盖,友好的错误提示 |
| 大规模数据 | 企业级数据量 | 分布式引擎 + 计算下推 |
| 跨源融合 | 不同来源的数据做关联分析 | 语言层原生支持跨源 JOIN |
InfiniSQL 不是又一个 SQL 方言。它是一门为 Agentic 工具调用范式量身定制的数据探索语言。
它的 load → select ... as → select ... as → ... 管道式设计,精确映射了 Agent "调用工具 → 获取结果 → 决策下一步 → 再次调用"的循环。每一次工具调用的产出(具名表)自然成为下一次调用的输入,无需额外的状态管理。
这就是为什么 InfiniSynapse 用 DeepSeek V3 就能获得优秀效果,而竞品即使用更强的模型写 Python 代码做数据分析也力不从心——不是模型的问题,是语言和范式的契合度决定了上限。
当竞品们在"如何让 LLM 更好地生成 Python 代码"这条路上厮杀时,InfiniSynapse 跳出了这个框架——它没有试图让 Agent 成为更好的程序员,而是让 Agent 成为更好的分析师。

InfiniSynapse —— 让数据直接说话。