The Agentic paradigm is reshaping how AI interacts with data. But a critical question remains unanswered: What "language" should an Agent use to operate on data?
Most Data Agent products chose Python — having LLMs generate pandas code and execute it in sandboxes. This path seems natural but grows increasingly narrow. InfiniSynapse took a fundamentally different approach: using InfiniSQL, a data analysis language designed for AI, as the Agent's tool language.
This article is not a feature overview. It is a technical inquiry: Why is InfiniSQL's language design structurally isomorphic to the Agentic tool-calling paradigm? And why does this isomorphism produce results far superior to the Python approach?
I. What the Agentic Paradigm Actually Means for Data Analysis
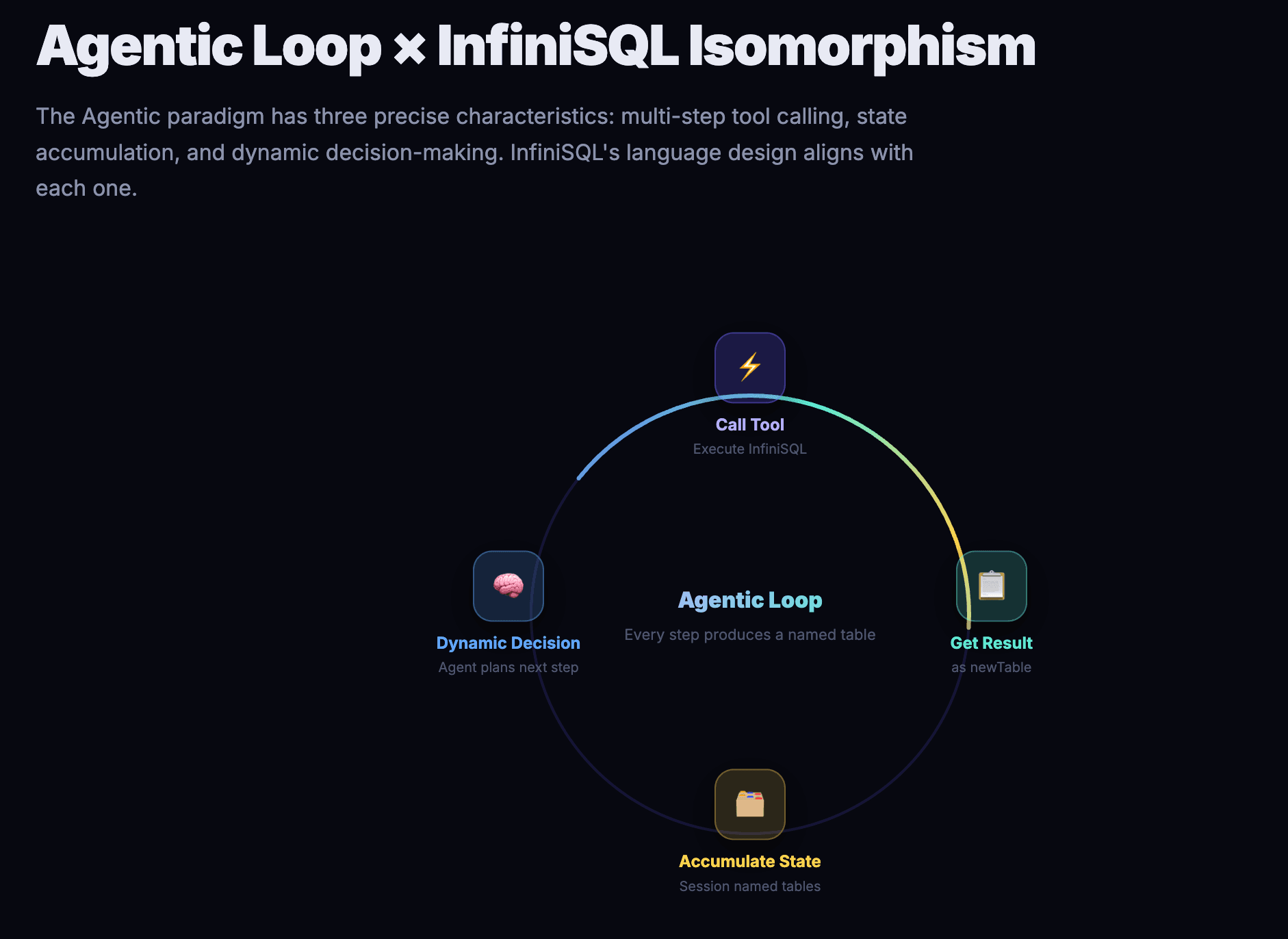
The Agentic paradigm is not a vague concept. In data analysis, it has three precise characteristics:
Multi-step tool calling. An Agent doesn't generate a final answer in one shot. Instead, it calls tools multiple times, acquiring partial information at each step, progressively converging toward complete insight. A single data analysis session may involve 10–50 tool calls — from inspecting table structures and exploratory sampling to dimensional drill-downs, anomaly detection, and cross-validation.
State accumulation. Results from prior calls must be referenceable by subsequent calls. The "East China sales data" the Agent found in step 3 must be directly usable in step 7, without re-querying. All intermediate results form a data exploration tree.
Dynamic decision-making. Each step's output determines the next step's direction. The Agent decides to drill into East China only after seeing anomalous data there; it decides to load a new data source only when customer dimensions are needed. This is not a pre-scripted workflow but real-time judgment based on data reality.
These three characteristics impose strict requirements on the tool language: the language must support low-cost state accumulation, dynamic data source integration, and an extremely low per-step error rate.
II. Why InfiniSQL's Language Design Precisely Aligns with These Three Characteristics
2.1 select ... as newTable: Native State Accumulation
InfiniSQL's syntax requires every select statement to end with as tableName. This is not syntactic sugar — it is a profound architectural decision.
Look at InfiniSQL's ANTLR grammar definition:
SELECT ~(';')* as tableName
And the engine's implementation: after a select finishes execution, the engine automatically registers the result as a Spark temporary view (df.createOrReplaceTempView(tableName)), referenceable by any subsequent statement within the entire session.
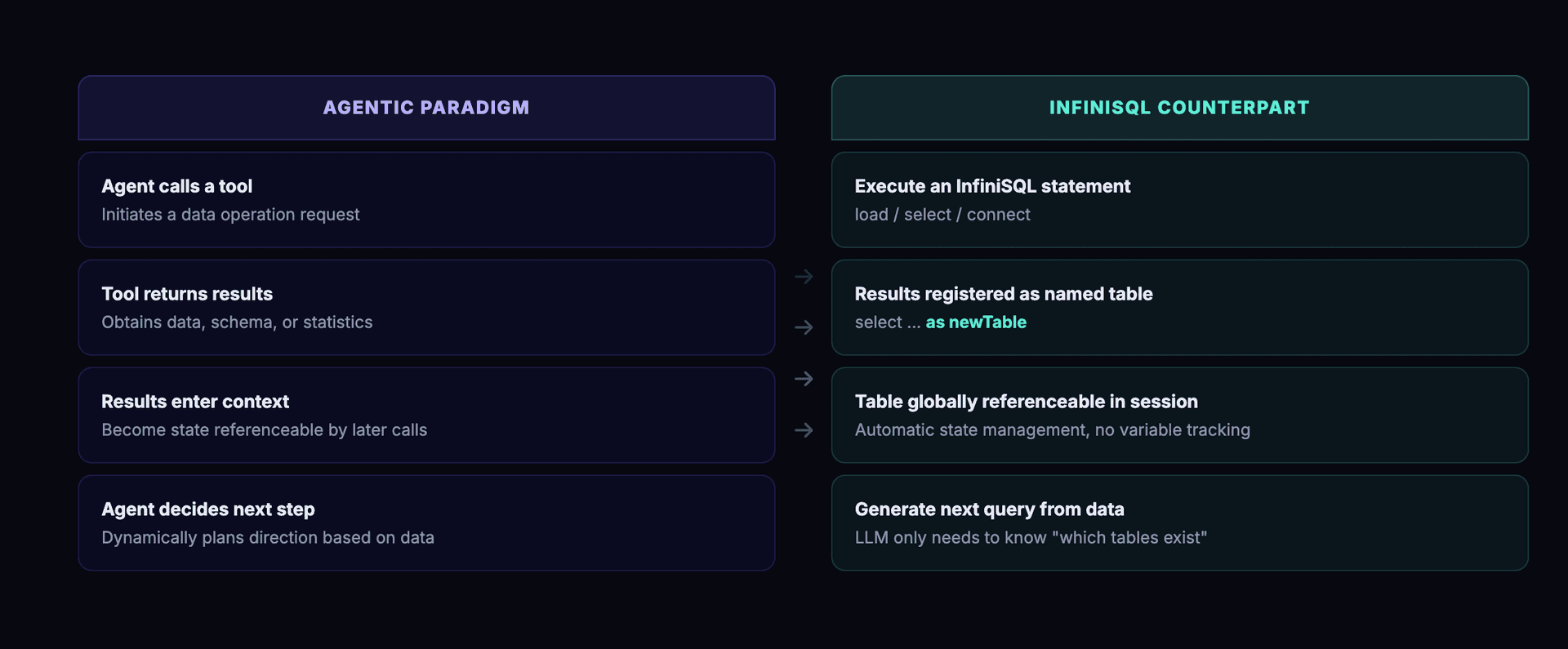
Every tool call (i.e., every InfiniSQL statement) automatically becomes a named table. No extra state management layer needed. No need for the Agent to remember previous variable names. This is a perfect structural isomorphism with the Agentic paradigm's state accumulation:
| Agentic Paradigm | InfiniSQL Counterpart |
|---|---|
| Agent calls a tool | Execute an InfiniSQL statement |
| Tool returns results | Results registered as a named table |
| Results enter Agent context | Table globally referenceable within session |
| Agent decides next action | Generate next query based on data results |
Standard SQL lacks this capability. A standard SELECT returns a result set that immediately vanishes. Reusing it requires CTEs, subqueries, or manually creating temporary tables — all of which increase LLM cognitive load and error probability.
2.2 load ... as tableName: Unified Abstraction for Cross-Source Data
InfiniSQL's load syntax abstracts any data source into a table:
-- Connect to local MySQL
connect jdbc where
url="jdbc:mysql://127.0.0.1:3306/business_db"
and driver="com.mysql.jdbc.Driver"
and user="xxx" and password="xxx"
as mysql_db;
-- Connect to cloud PostgreSQL
connect jdbc where
url="jdbc:postgresql://cloud.example.com:5432/analytics"
and driver="org.postgresql.Driver"
and user="xxx" and password="xxx"
as pg_cloud;
-- Load data from different sources — they coexist in the same session
load jdbc.`mysql_db.orders` as orders;
load jdbc.`pg_cloud.customers` as customers;
load csv.`/data/local_sales.csv` as local_sales;
After three load statements, data from a local file, a local MySQL, and a remote cloud PostgreSQL coexist as three tables in the same session, ready for direct JOINs:
select o.order_id, c.name, l.region
from orders o
left join customers c on o.customer_id = c.id
left join local_sales l on o.order_id = l.order_id
as cross_source_analysis;
For the Agentic paradigm, this means the Agent can dynamically load new data sources at any point during exploration. Need to compare Excel data? Generate one load statement — the new data is immediately available, and all previously explored tables remain intact. No environment rebuilding. No pre-configured ETL pipelines.
2.3 Shared Session: A Persistent Workspace for Agentic Exploration
InfiniSQL's session mechanism (sessionPerUser / sessionPerRequest) and variable scoping (request / session / application) provide the Agent with a persistent workspace:
- Session-level tables remain valid throughout the entire conversation
- A table loaded in step 1 is still referenceable at step 20
- Every
select ... as someTableforms a retraceable data exploration tree within the session - Variables set to
sessionscope can be reused across statements
This is exactly what the Agentic paradigm requires: a workspace with memory that accumulates state.
III. Why the "Write Python Code" Approach is a Structural Disadvantage
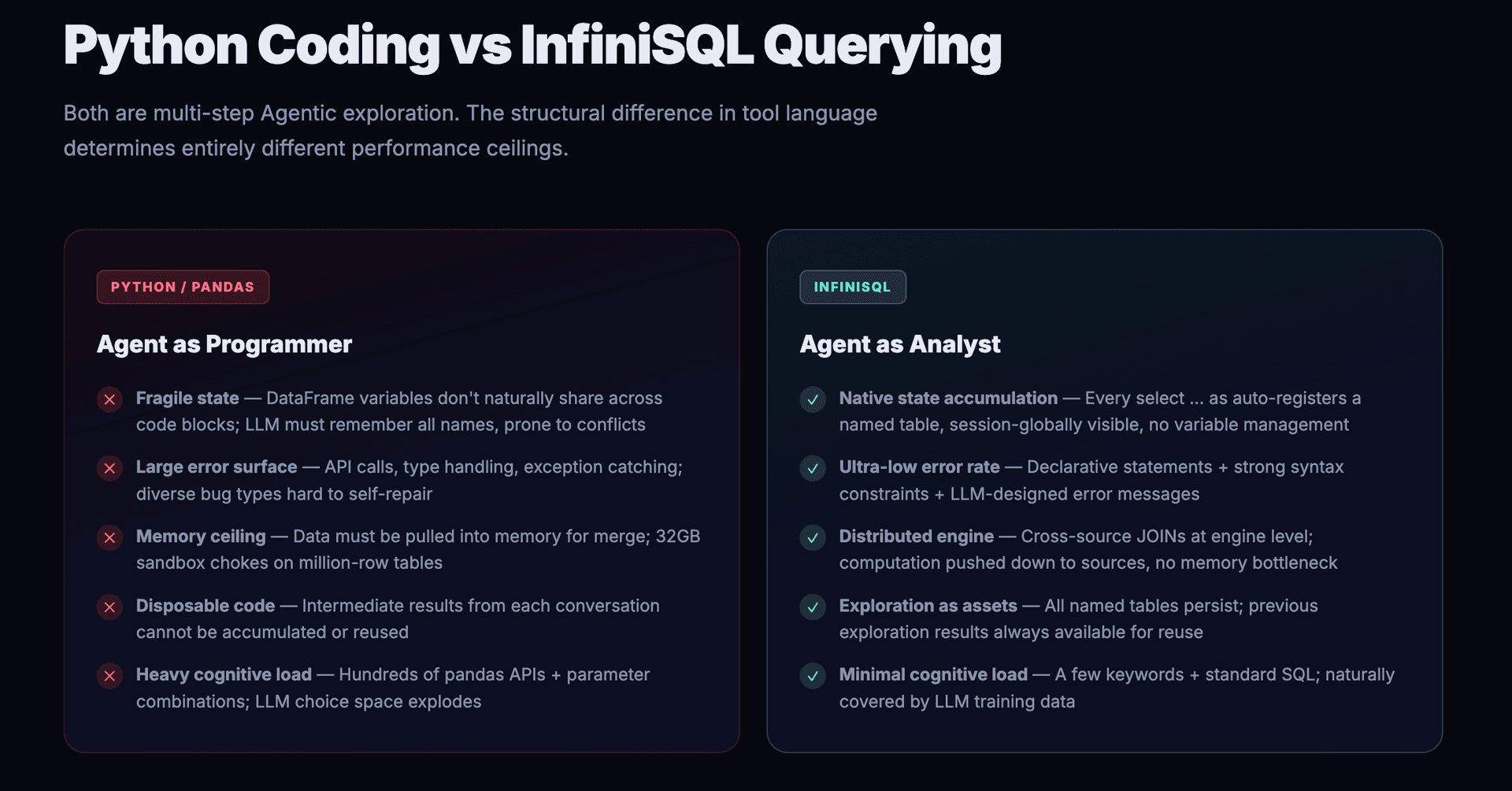
Competitors (Julius AI, camelAI, Fabi.ai, etc.) implement the Agentic paradigm by having LLMs generate Python code (primarily pandas), executed in sandboxes. In multi-step Agentic exploration scenarios, this approach suffers from five structural disadvantages:
3.1 State Management is Fragile
In the Python approach, each Agent call generates a code block. The previous block's result lives in a DataFrame variable; the next block must reference it, so the LLM must "remember" the variable name.
The problem: as exploration steps increase, the variable namespace grows increasingly complex. The LLM may forget whether it used df_orders_filtered or filtered_orders, or accidentally overwrite a step-3 variable at step 15.
InfiniSQL has no such problem. A table registered via select ... as orders_filtered has a deterministic, globally visible name. The Agent only needs to know "what tables exist in the current session" — a flat list, not a dependency tree of code variables.
3.2 The Error Surface Per Step is Too Large
Generating a Python code block involves: API calls (pd.read_sql(), pd.merge(), groupby()), type handling (astype(), to_datetime()), exception handling (try/except), string concatenation (SQL injection risks), and more. The LLM can err at any of these points, with diverse error types — syntax errors, logic errors, API version incompatibility, memory overflow.
Each InfiniSQL call is a single declarative statement. Syntax constraints are strong (must end with as tableName), and the query body is standard SQL. The LLM's error surface is drastically compressed.
More critically, InfiniSQL's error messages are designed for LLMs:
InfiniSQL Parser error: Select statement is missing 'as tableName' clause.
InfiniSQL select statements must end with 'as tableName'.
Example: select * from table1 as result_table;
When the LLM forgets as tableName, the error message tells it exactly what to fix — Agent self-correction requires almost no additional reasoning.
3.3 Multi-Source Fusion Hits a Memory Ceiling
The Python/pandas approach to cross-source analysis: pull data from database A into memory (pd.read_sql()), pull data from database B into memory, then pd.merge().
In a 32GB sandbox, million-row tables cause lag. Forget about joining local Excel with a remote Hive data warehouse.
InfiniSQL's cross-source JOIN runs on a distributed engine. The directQuery mechanism pushes native queries down to the data source:
load jdbc.`mysql_instance.large_table` where directQuery='''
select region, sum(amount) as total from large_table group by region
''' as aggregated_result;
Aggregation happens on the MySQL side; only results come back — this is computation pushdown, not data migration.
3.4 Exploration Assets Cannot Be Accumulated
One of Julius AI's most-complained-about pain points: code generated in each conversation is disposable — previously written code or constructed data views cannot be reused.
This is a structural limitation of the Python approach — there's no unified namespace between code blocks, and DataFrame variables from previous conversations vanish.
In InfiniSQL's session, all tables produced by load and select ... as persist. The Agent can revisit previous exploration results at any time and build further analysis on existing tables. The exploration process itself is the accumulation of assets.
3.5 LLM Cognitive Load Is on a Different Order of Magnitude
pandas has hundreds of APIs (read_csv, merge, groupby, pivot_table, apply, melt, stack, unstack...), each with multiple parameter combinations. The LLM must choose within this enormous API space.
InfiniSQL's core keywords are just: load, connect, select ... as, save, set. The query body is compatible with standard SQL, which LLMs have seen abundantly in training data. The cognitive load gap is an order of magnitude.
| Dimension | Python/pandas | InfiniSQL |
|---|---|---|
| State accumulation | Variable namespaces, conflict-prone, easy to forget | Named tables auto-registered, session-globally visible |
| Per-step error rate | High (many APIs, complex types, exception handling) | Very low (simple syntax, strong constraints, LLM-friendly errors) |
| Multi-source fusion | Memory bottleneck (pull data → merge) | Distributed engine + computation pushdown |
| Exploration asset reuse | Disposable code, hard to reuse | Named tables persist, always referenceable |
| LLM cognitive load | Hundreds of APIs, parameter combinatorial explosion | A few keywords + standard SQL |
Human data analysts do analysis with SQL, not Python — Agents should do the same.
There's an often-overlooked fact: SQL was born for data. When a human analyst sits down in front of a database, the first instinct is to write SQL, not a Python script. Why? Because SQL is declarative — you say what you want, not how to get it. SELECT region, SUM(amount) FROM orders GROUP BY region expresses an analytical intent in one sentence. The Python equivalent requires df.groupby('region')['amount'].sum().reset_index() plus a pile of type conversions and exception handling.
Agents face the exact same problem as humans: extracting insight from data. If humans chose SQL as the language for talking to data, there's no reason Agents should detour through Python.
What InfiniSQL does is adapt standard SQL to better fit the Agentic paradigm:
- Standard SQL's
SELECTresults are ephemeral — InfiniSQL addsas newTable, making every query automatically persist as a named table in the session - Standard SQL can't span data sources — InfiniSQL adds
connect+load, letting the Agent dynamically integrate any data source - Standard SQL has no machine learning — InfiniSQL adds
train+register, embedding model training and prediction into the same pipeline
SQL itself is already the right choice. InfiniSQL simply makes it better suited for Agents. This isn't "inventing a new language" — it's precisely augmenting the most natural language for data analysis with the state accumulation, multi-source fusion, and pipeline capabilities that the Agentic paradigm demands.
IV. A Deeper Fit: Machine Learning as an Extension of "Tables"
The alignment between InfiniSQL and the Agentic paradigm goes beyond data querying — it seamlessly integrates machine learning into the same pipeline.
Traditional machine learning is inherently data-centric: prepare features → train model → predict → evaluate. In the Python world, this requires jumping from pandas to scikit-learn or PyTorch — an entirely different API ecosystem. In InfiniSQL, machine learning is a natural extension of the SQL pipeline — the input to model training is simply the "table" produced by select after feature engineering.
4.1 Feature Engineering → Training → Prediction: One Unified Pipeline
Here's a complete InfiniSQL machine learning workflow:
-- Step 1: Load raw data (identical load syntax as data exploration)
load jdbc.`mysql_db.iris_data` as rawData;
-- Step 2: Feature engineering — standard SQL select
select
vec_dense(array(sepal_length, sepal_width, petal_length, petal_width)) as features,
cast(species as double) as label
from rawData as trainData;
-- Step 3: Train model — input is the "trainData" table from the previous step
train trainData as RandomForest.`/models/iris_model` where
keepVersion="true"
and evaluateTable="trainData"
and `fitParam.0.labelCol`="label"
and `fitParam.0.featuresCol`="features"
and `fitParam.0.maxDepth`="5"
and `fitParam.0.numTrees`="10";
-- Step 4: Register model as a SQL function
register RandomForest.`/models/iris_model` as iris_predict;
-- Step 5: Predict — call the model function directly in select
select
features,
label as actual,
vec_argmax(iris_predict(features)) as predicted
from trainData as predictions;
Key characteristics of this workflow:
train trainData— thetrainDatais the table produced by the previousselect ... as trainData. Feature engineering results flow directly into training with no format conversion, no API switching.register ... as iris_predictturns the trained model into a SQL function — callable in any subsequentselectstatement.- The entire flow from
loadtoselect(feature engineering) totraintoregistertoselect(prediction) stays in the same session, using the same language.
4.2 Why This Matters for the Agentic Paradigm
During Agentic data exploration, the Agent often discovers predictable patterns in the data — for example, finding that VIP customer purchasing behavior follows a pattern worth modeling.
In the Python approach, the Agent must:
- Switch from pandas to scikit-learn
- Convert DataFrames to numpy arrays
- Learn an entirely different API (
fit(),predict(),score()) - Handle model serialization and loading
In InfiniSQL, the Agent's operations are completely seamless:
- Use
selectfor feature engineering (what it's been doing all along) - Use
trainto train (input is the table it justselect-ed) - Use
registerto register the model as a function - Use
select+ model function for prediction (still writingselect)
The Agent doesn't switch languages, doesn't learn new APIs, doesn't convert formats. Machine learning adds just two keywords — train and register — while everything else — data format (tables), operation mode (select), state management (session) — remains identical.
This means InfiniSQL's Agentic pipeline can naturally extend from "data querying" to "predictive modeling" without leaving the paradigm. The Agent's cognitive load barely increases, but its capability boundary expands dramatically.
4.3 Unified Semantics: Everything Is a Table
At a deeper level, InfiniSQL achieves a unified semantic: everything is a table, every operation produces a table.
| Operation | Syntax | Input | Output |
|---|---|---|---|
| Load data | load ... as | Data source | Table |
| Data exploration | select ... as | Table | Table |
| Feature engineering | select ... as | Table | Table |
| Model training | train table as ... | Table | Model |
| Model registration | register ... as func | Model | SQL function |
| Prediction | select func(x) ... as | Table + Function | Table |
From load to data exploration to feature engineering to training to prediction, data always flows in the form of "tables." The Agent doesn't need to understand "the difference between DataFrame and numpy array" or handle "model object serialization" — it only needs to know how to write select and train.
This is why InfiniSynapse can embed complete machine learning capabilities (RandomForest, LinearRegression, NaiveBayes, KMeans, etc.), while competitors — even when calling scikit-learn through Python — struggle to reliably execute machine learning tasks in Agentic scenarios. Switching API ecosystems means switching cognitive modes, and every switch is a risk point for Agent errors.
V. A Concrete Agentic Exploration Walkthrough
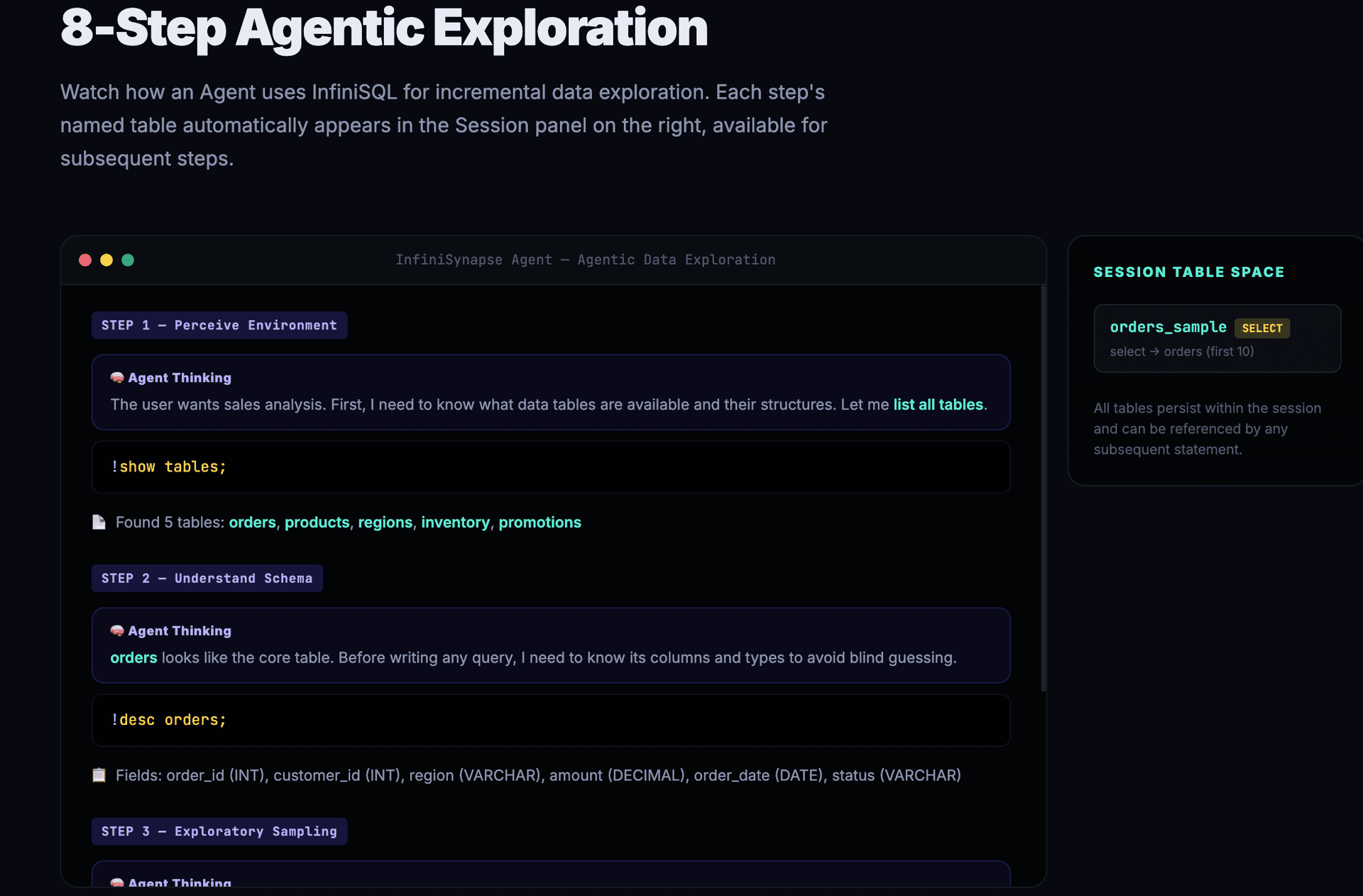
The following shows an InfiniSynapse Agent using InfiniSQL for a real data exploration. Observe how each step produces a named table and how subsequent steps reference them.
The Agent first perceives the environment, understanding available data tables and field structures:
After confirming schema, the Agent begins exploratory sampling to verify data quality:
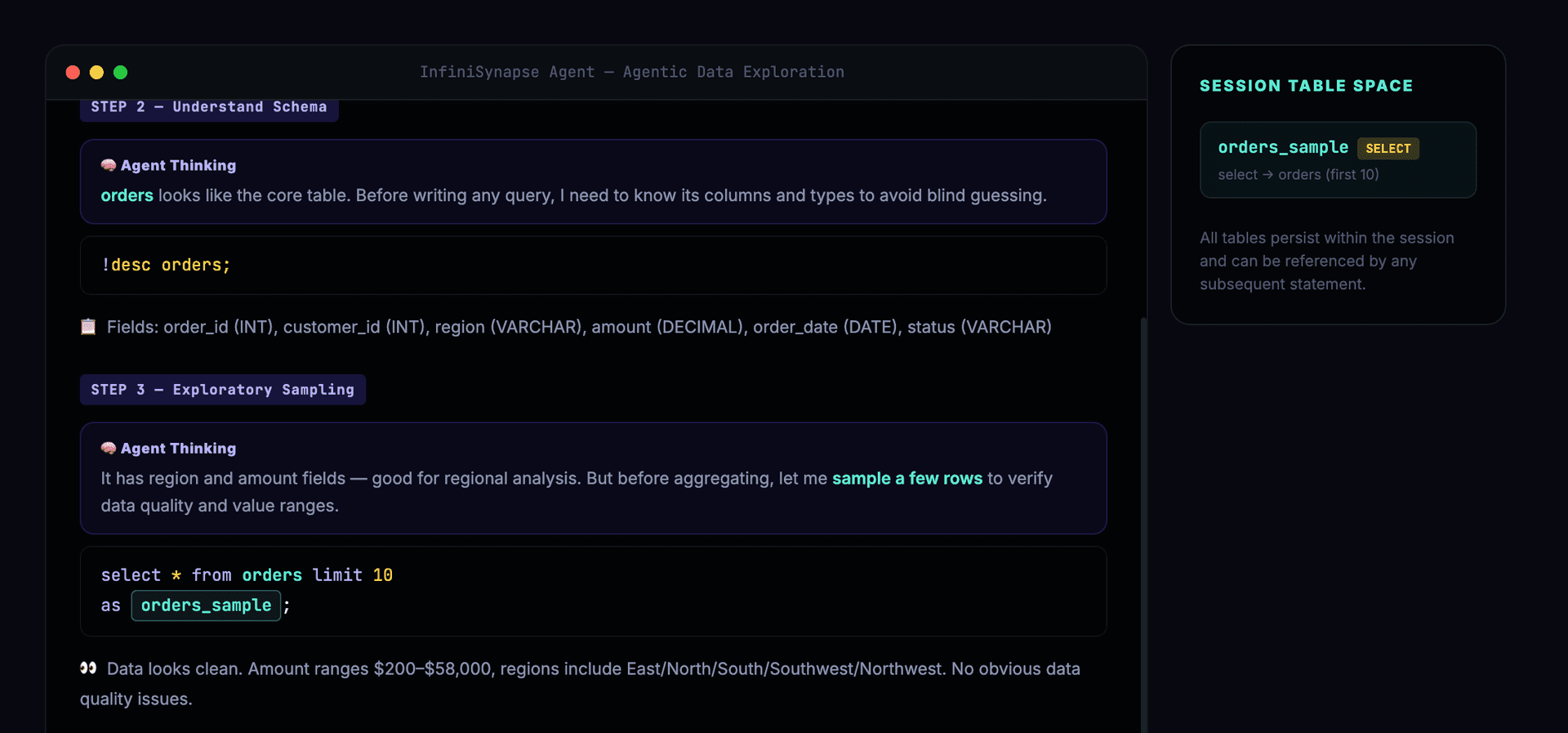
With clean data confirmed, the Agent aggregates by dimension and discovers the East China anomaly:
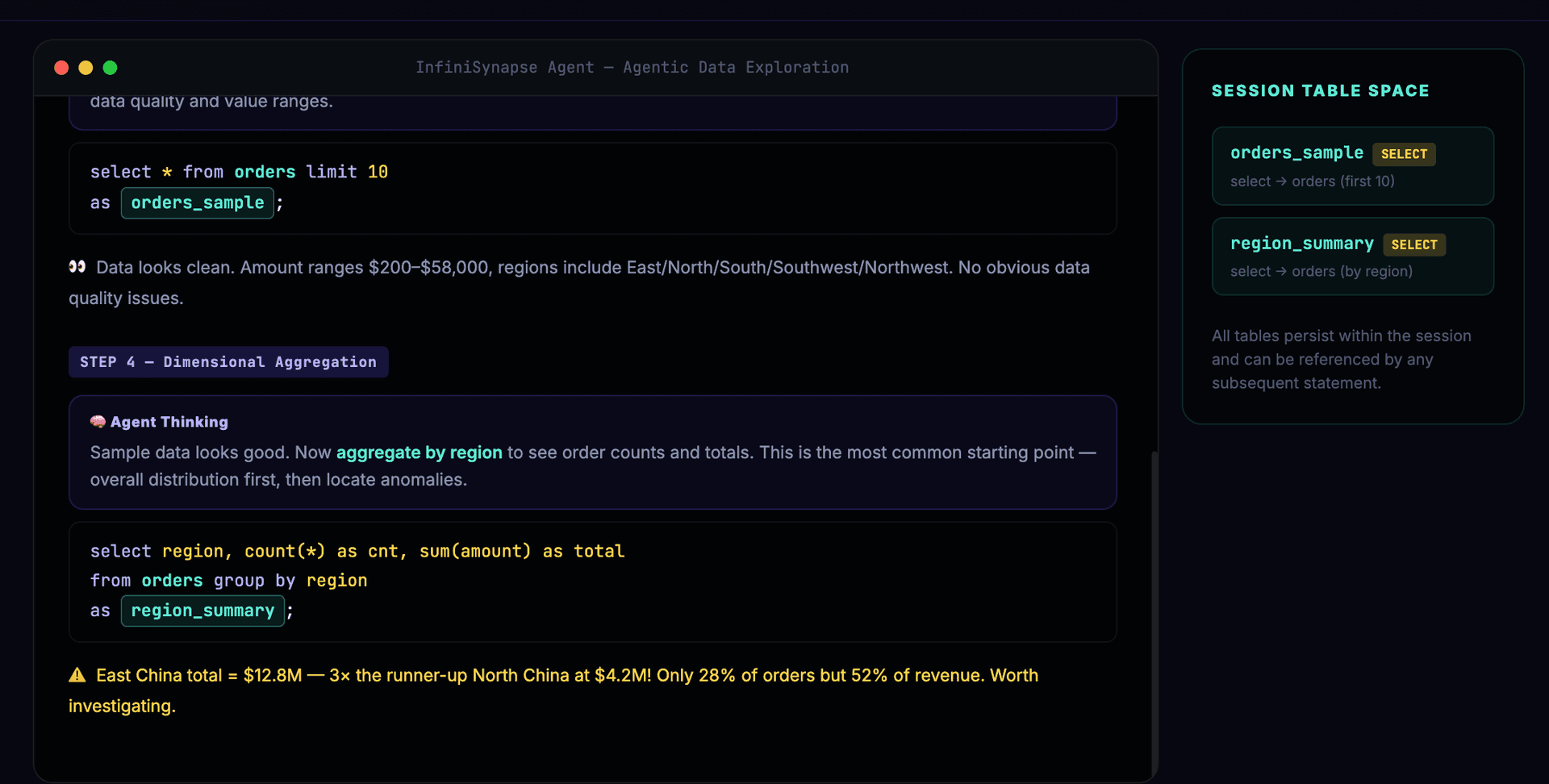
The Agent decides to drill into East China, finding large orders concentrated among a few customers:
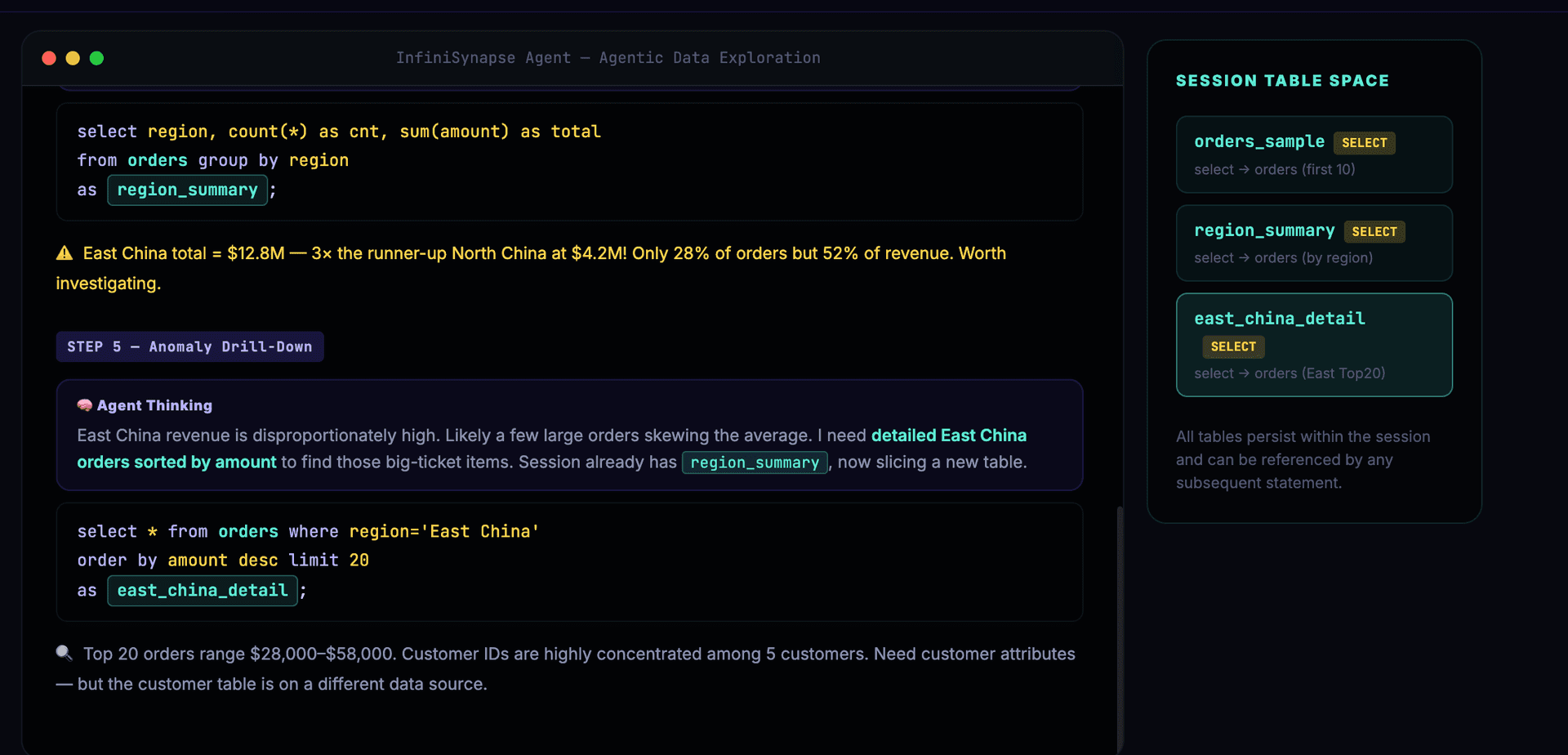
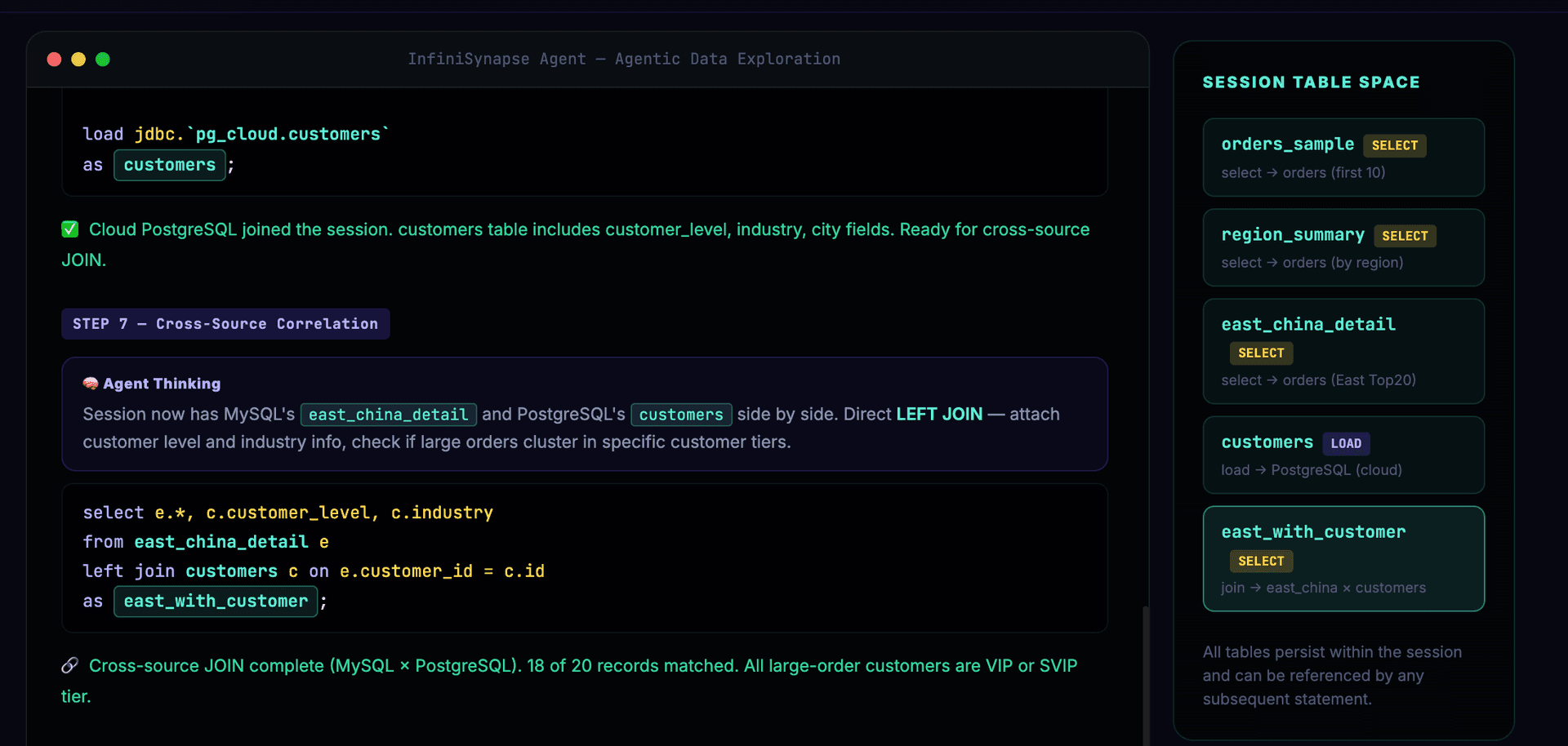
Customer dimension data is needed — the Agent dynamically integrates cloud PostgreSQL:
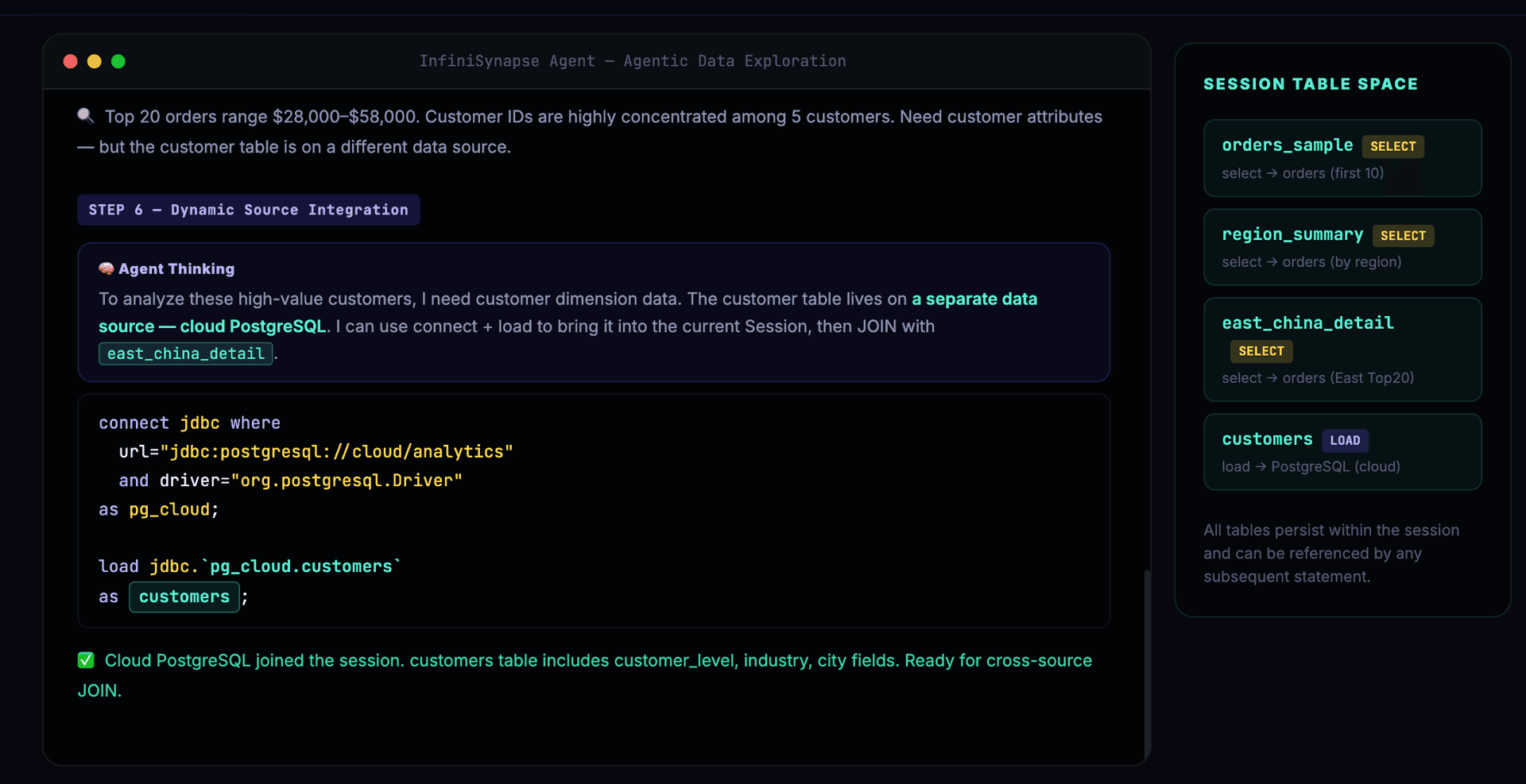
Cross-source JOIN, correlating MySQL order data with PostgreSQL customer data:
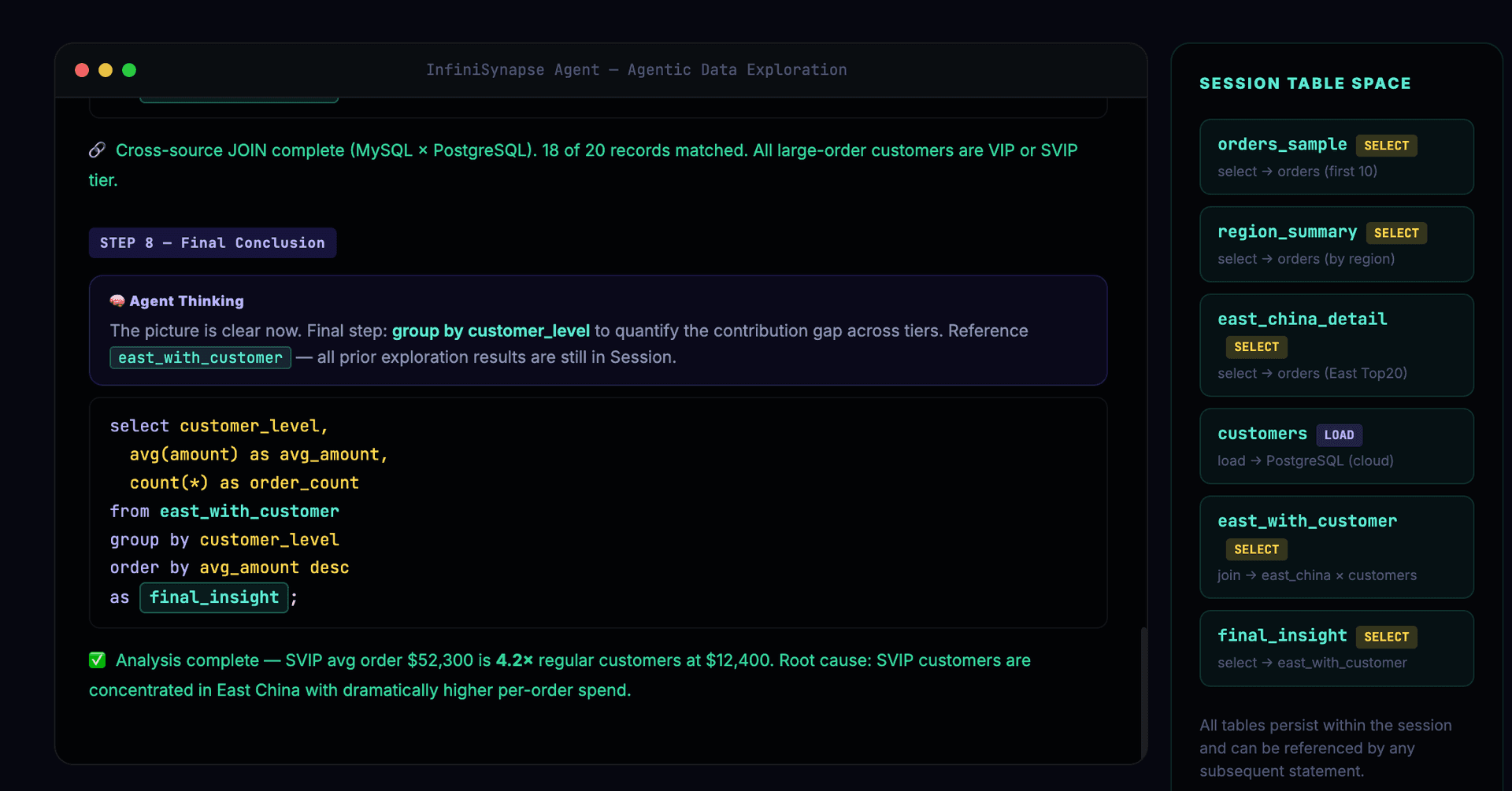
Final conclusion reached — the Session panel shows all named tables from the exploration:
Here is the complete InfiniSQL code for all 8 steps:
-- Step 1: Agent checks what data sources are available
!show tables;
-- Step 2: Inspect the orders table structure
!desc orders;
-- Step 3: Exploratory sampling to understand the data shape
select * from orders limit 10 as orders_sample;
-- Step 4: Seeing the data, Agent decides to aggregate by region
select region, count(*) as cnt, sum(amount) as total
from orders group by region
as region_summary;
-- Step 5: Agent spots East China anomaly, drills down
select * from orders where region='East China'
order by amount desc limit 20
as east_china_detail;
-- Step 6: Customer dimension needed — dynamically load cloud PostgreSQL
connect jdbc where
url="jdbc:postgresql://cloud.example.com/analytics"
and driver="org.postgresql.Driver"
and user="xxx" and password="xxx"
as pg_cloud;
load jdbc.`pg_cloud.customers` as customers;
-- Step 7: Cross-source JOIN — reusing step 5 results
select e.*, c.customer_level, c.industry
from east_china_detail e
left join customers c on e.customer_id = c.id
as east_china_with_customer;
-- Step 8: Final analysis based on all prior exploration
select customer_level,
avg(amount) as avg_amount,
count(*) as order_count,
sum(amount) as total_amount
from east_china_with_customer
group by customer_level
order by total_amount desc
as final_insight;
8 steps of exploration, producing 6 named tables (orders_sample, region_summary, east_china_detail, customers, east_china_with_customer, final_insight), dynamically integrating a new data source (cloud PostgreSQL) mid-exploration.
Each step is short, independent, and verifiable. The Agent decides to drill into East China only after seeing region_summary results; it decides to load the customer table only after seeing east_china_detail data. This is the Agentic paradigm's "small-step exploration, dynamic decision-making" in action.
If the same process were implemented in Python:
- Steps 6-7 would require writing
psycopg2connection code,pd.read_sql()to pull data, andpd.merge()to join — at least 15-20 lines of code involving 3-4 different APIs - Step 5's result stored in
df_east_chinavariable must be accurately referenced in step 7 - If any intermediate step runs out of memory, all subsequent steps fail
With InfiniSQL, each step is 1–5 lines of declarative statements. The Agent's error probability and correction cost are both extremely low.
VI. Why This Combination Produces Superior Results
6.1 Reduces Agent's Per-Step Cognitive Cost
The Agentic paradigm's effectiveness depends on how long the exploration chain can extend. If each step's error rate is 10%, the probability of 10 consecutive correct steps is only 35%; if the per-step error rate drops to 2%, the probability rises to 82%.
InfiniSQL's minimal syntax and strong constraints push the per-step error rate to near-zero, enabling Agents to execute 20-50 steps of deep exploration without derailing. This is why InfiniSynapse achieves excellent results with DeepSeek V3 — it's not about a stronger model, it's about lower cognitive load per step.
6.2 Enables Truly Incremental Exploration
The select ... as newTable design gives each Agent exploration step a deterministic output. The Agent doesn't need to get everything right in one massive nested SQL. Instead, it can:
- Write a simple query to see the data
- Write a second query to filter based on results
- Aggregate based on filtered results
- Compare based on aggregated results
Each step is simple enough for the Agent to get right; each step's result is automatically saved for later use. This is the linguistic foundation of InfiniSynapse Agent's "small-step exploration, self-correction" strategy.
6.3 Cross-Source Fusion as a Native Language Capability
In real enterprise environments, data is scattered across different systems, different clouds, even different geographies. The Agentic paradigm's value lies in dynamically discovering which data sources are needed and integrating them on the fly.
InfiniSQL's connect + load mechanism perfectly supports this:
connectonly registers connection info without actually pulling dataloadloads on demand, registering as a session tabledirectQuerypushes computation down to the data source- Cross-source JOINs execute on the distributed engine
The Agent can integrate new data sources at any exploration stage — local Excel, remote MySQL, cloud Snowflake — all in the same session, freely combinable.
Competitors' Python/pandas approach cannot achieve this: different data sources require different Python connection libraries (mysql-connector, psycopg2, snowflake-connector...), all data must be pulled into memory for merging, and memory becomes the bottleneck.
6.4 Self-Correction Cost Approaches Zero
When an Agent's query returns anomalous results (empty table, unexpected data), correction is simply: generate one new select statement. No need to backtrack and modify an entire Python code block. No need to re-run the data loading pipeline.
InfiniSQL's error messages are designed for Agents — not human-readable stack traces, but structured messages with correction examples. Upon reading the error, the Agent knows exactly what to fix.
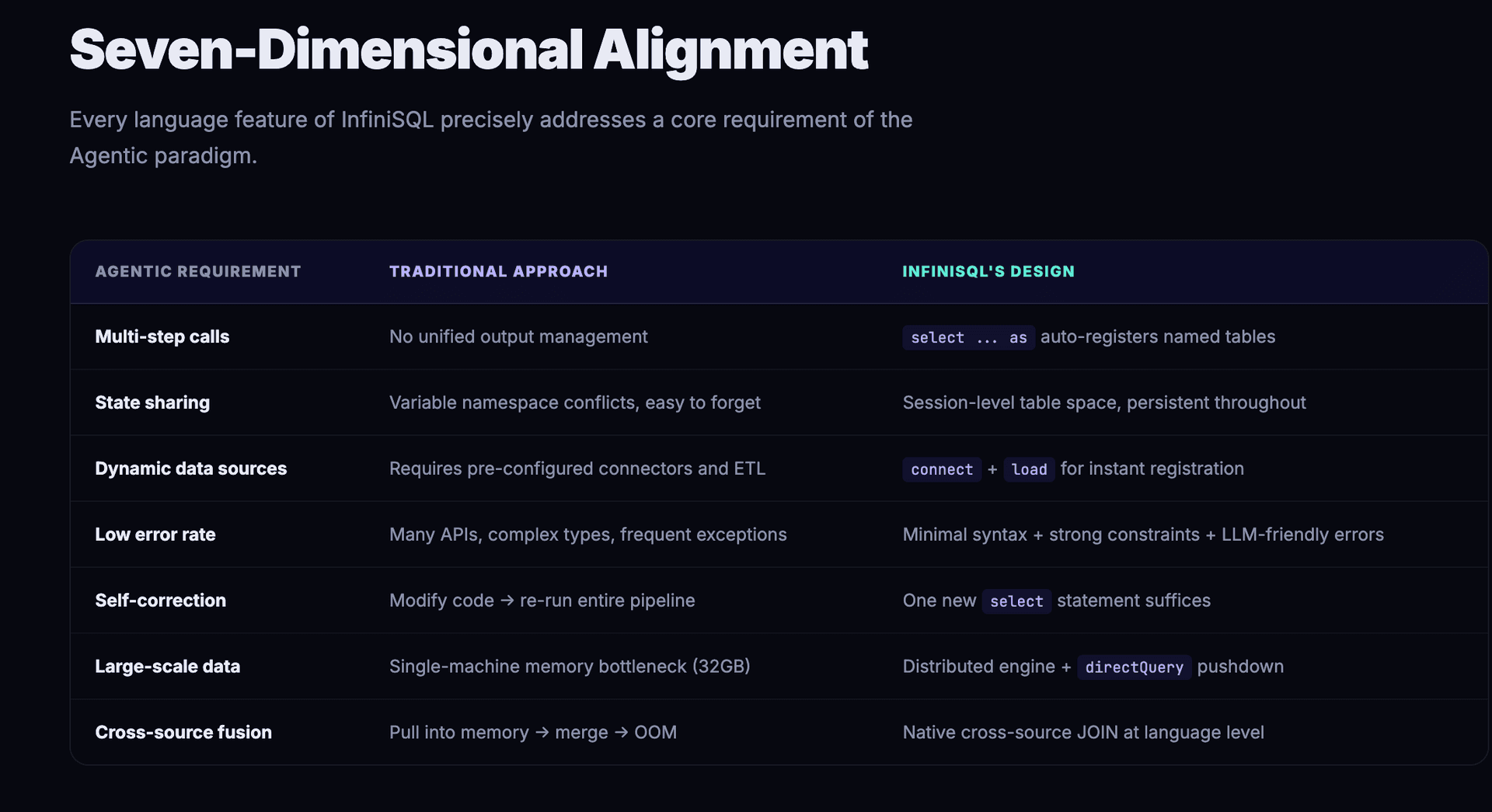
VII. Conclusion: The Language Determines the Agent's Ceiling
| Characteristic | Agentic Paradigm Requirement | InfiniSQL's Language Design |
|---|---|---|
| Multi-step calls | Each step produces results referenceable later | select ... as newTable auto-registers named tables |
| State sharing | All steps share a single context | Session-level table space, persistent throughout |
| Dynamic data sources | Need to integrate new data mid-exploration | connect + load for instant registration |
| Low error rate | High-frequency calls demand per-step reliability | Minimal syntax, extremely low LLM cognitive load |
| Self-correction | Low-cost recovery from errors | One new select suffices; friendly error messages |
| Large-scale data | Enterprise-grade data volumes | Distributed engine + computation pushdown |
| Cross-source fusion | Correlating data from different sources | Native cross-source JOIN at the language level |
InfiniSQL is not another SQL dialect. It is a data exploration language purpose-built for the Agentic tool-calling paradigm.
Its load → select ... as → select ... as → ... pipeline design precisely maps to the Agent's "call tool → get result → decide next step → call again" loop. Each tool call's output (a named table) naturally becomes the next call's input, with no extra state management needed.
This is why InfiniSynapse achieves excellent results with DeepSeek V3, while competitors struggle even with stronger models generating Python code for data analysis — it's not about the model; the fit between language and paradigm determines the ceiling.
While competitors battle over "how to make LLMs generate better Python code," InfiniSynapse leapt beyond that frame — it didn't try to make the Agent a better programmer; it made the Agent a better analyst.

InfiniSynapse — Let data speak directly.